事故现场
昨晚0点起某系统多个监控指标报警,关键埋点调用量大幅下滑,小时级调用量同比昨日下滑到2%。
背景
该应用通过MQ消费多个数据源进行业务逻辑处理,结果写入关系数据库。
每日消费消息有数千万条。
上一次发版时间8月2日,期间无异常。
初步分析
早上上班后检查该应用所有埋点监控数据,发现所有埋点同比昨日仅有5%,且没有任何错误埋点。当时已经是早上八点半,今天已过三分之一,理论上各埋点同比应该在33%左右。该情况表明应用有问题,需要登录服务器检查。
在服务器上发现,该应用日志正常,CPU负载120%,占满一个核心。
初步判定,可能是代码有BUG,导致CPU飚高,影响业务处理。
此时其实有点疑问,如果业务处理变慢,星尘监控的埋点耗时应该变大,并且有些埋点跟业务处理无关,不应该数据下降那么多。
先来分析解决CPU飚高的问题,现在dotTrace命令行工具,在服务器上对应用进程抓30秒数据回来。
./dottrace attach 62777 --save-to=../segment.dtp --timeout=30s把dtp包下载回来本地,dotTrace打开分析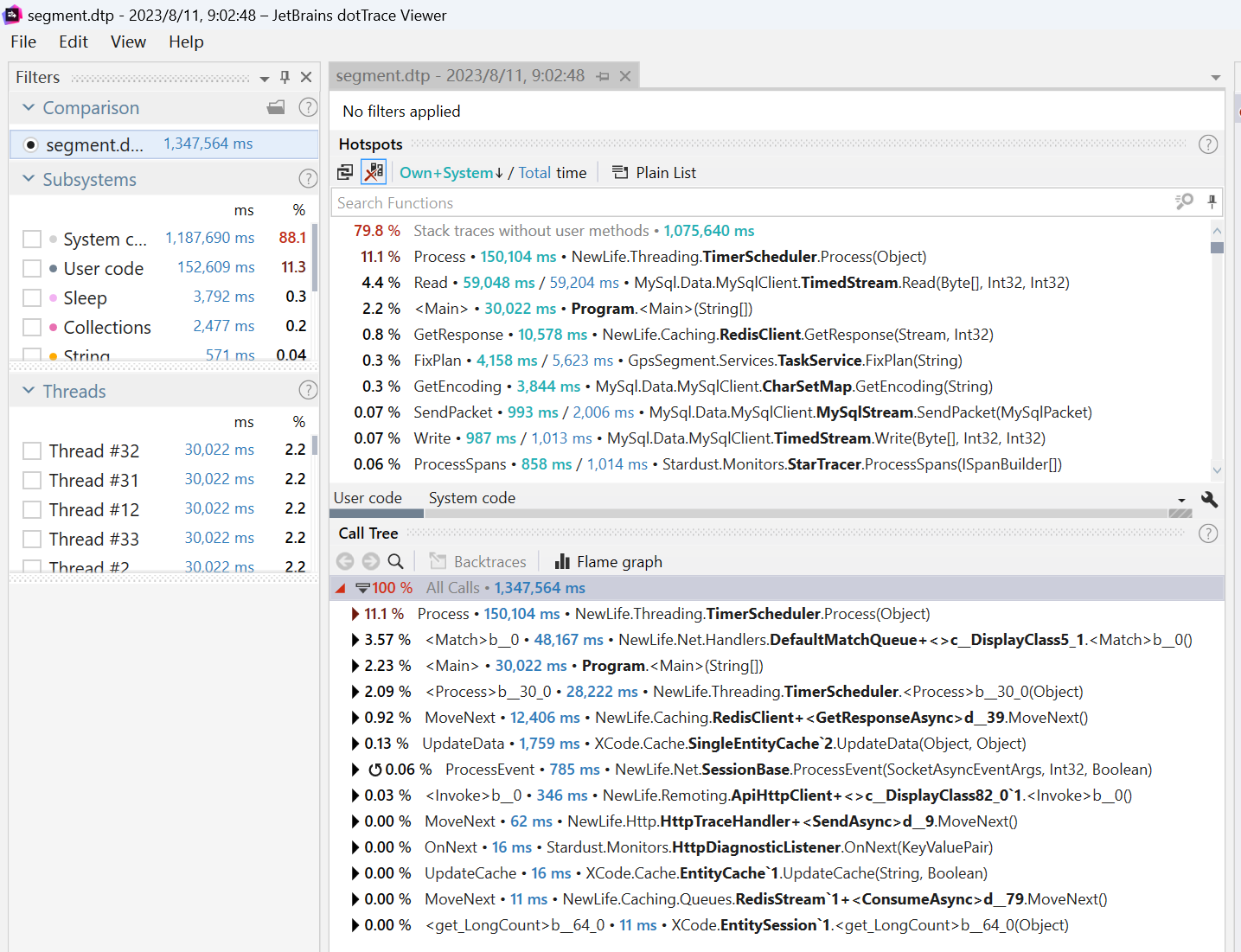
貌似没有什么异常,每个调用都中规中矩。
至此,线索中断。
柳暗花明
早几天测试环境刚好遇到一个事情,星尘所在SQLite在凌晨1点左右,数据库锁住了,导致应用埋点监控异常。实际上是那段时间,所有监控数据都无法落库。导致我以为应用出问题。
生产环境的星尘跑在物理机MySql上,不会出现SQLite锁,但可能是别的问题。于是检查生产星尘StarServer的埋点监控,收获很大!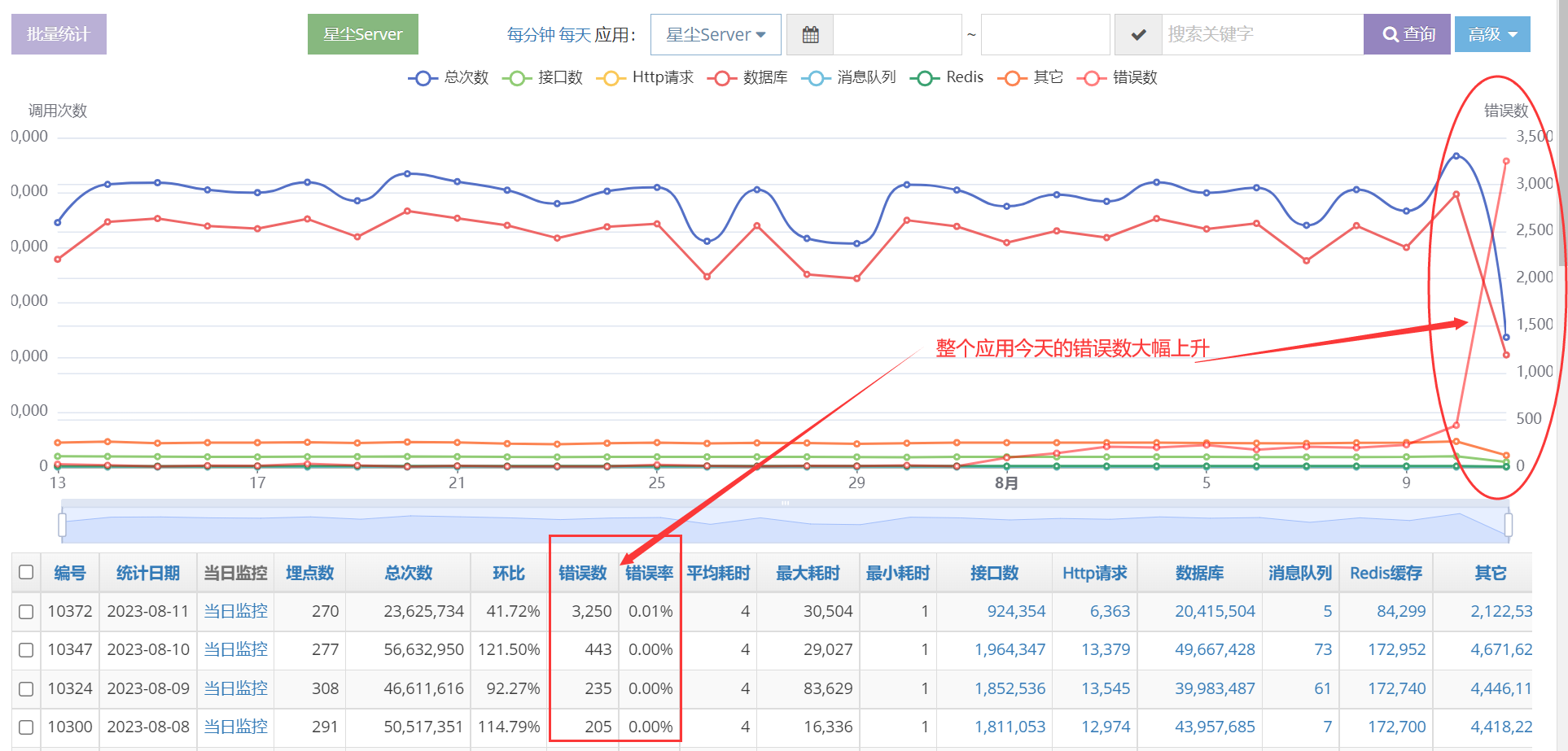
StarServer今天的错误数大幅上升,肯定是出问题了。点进去看今天的埋点情况,按照错误数排序。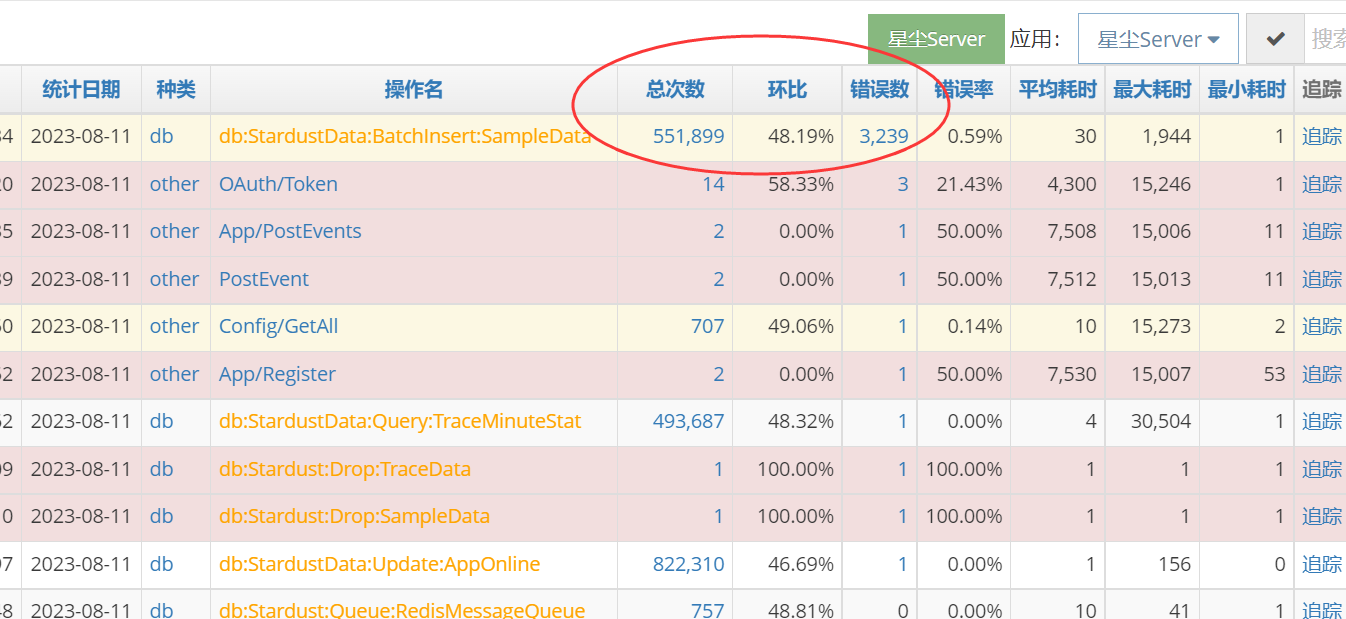
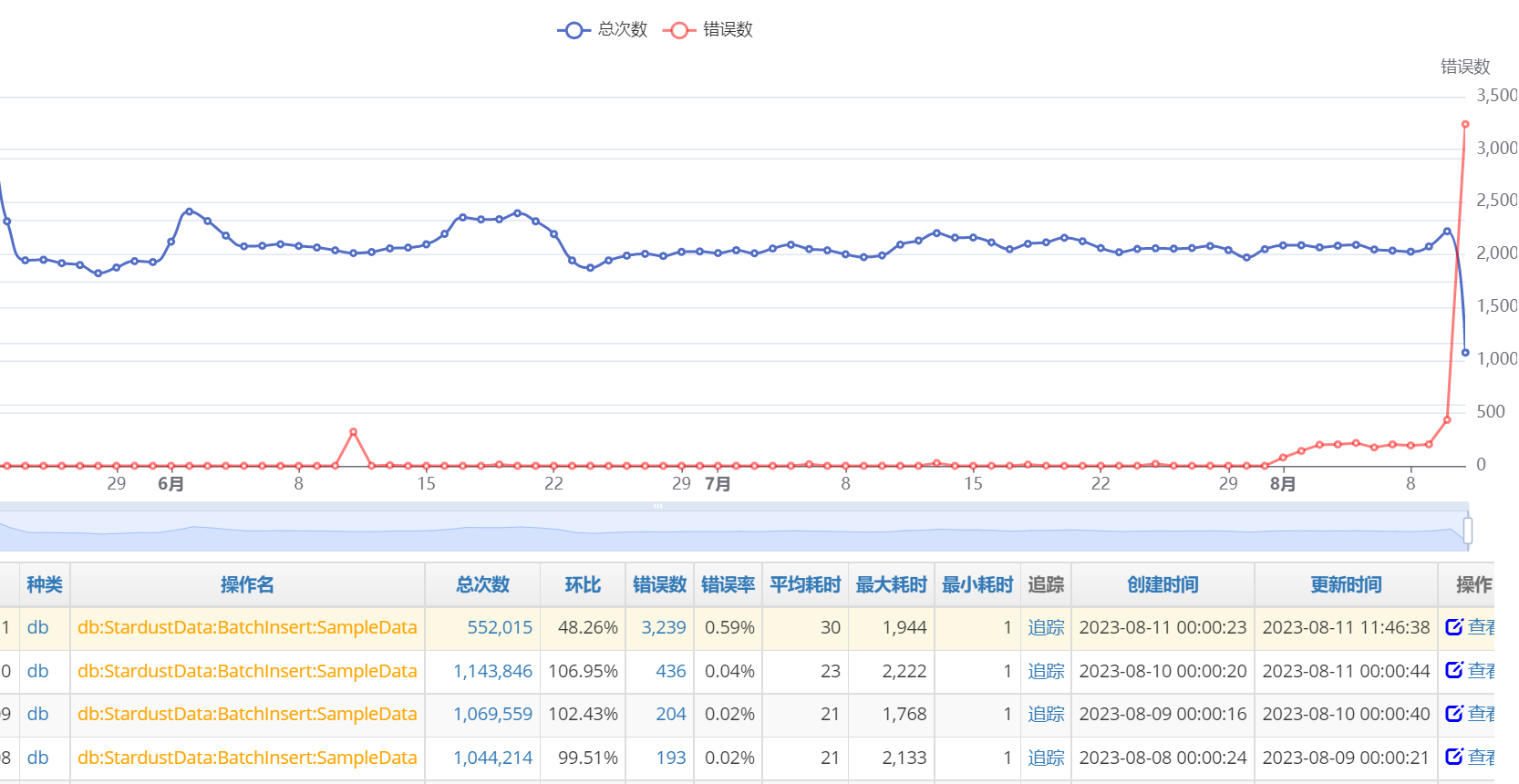
查看小时级曲线
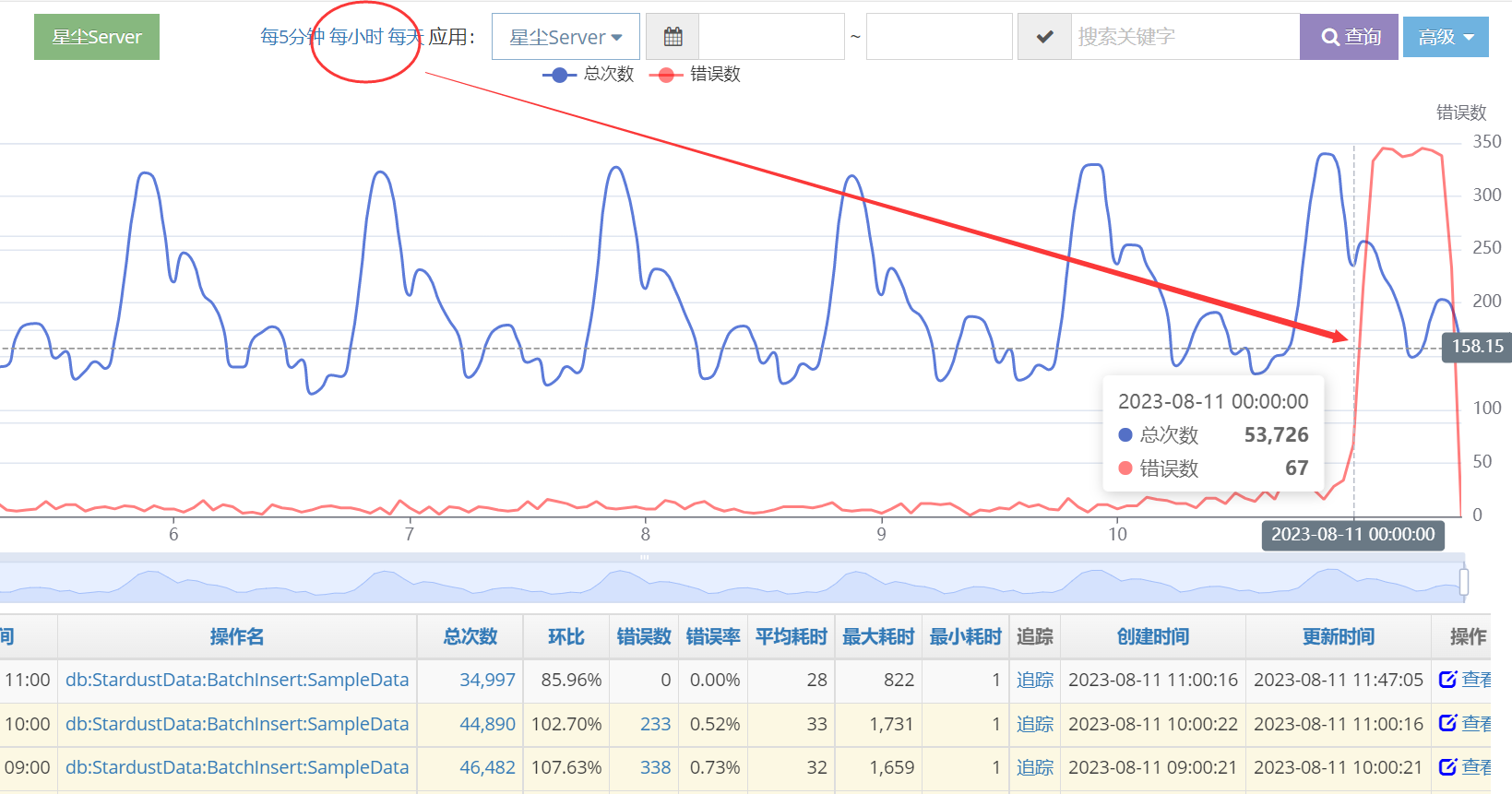
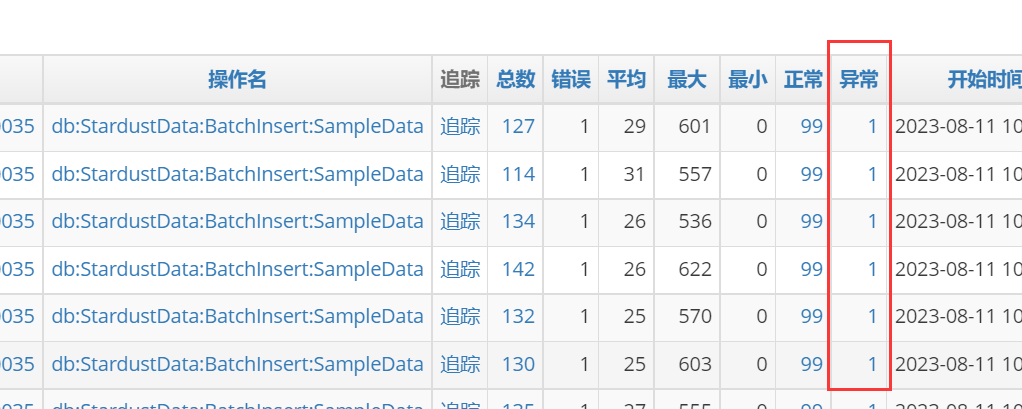
果然是0点开始出问题。点击错误数进去,如上图的233或338,挑选几个追踪进去看看。
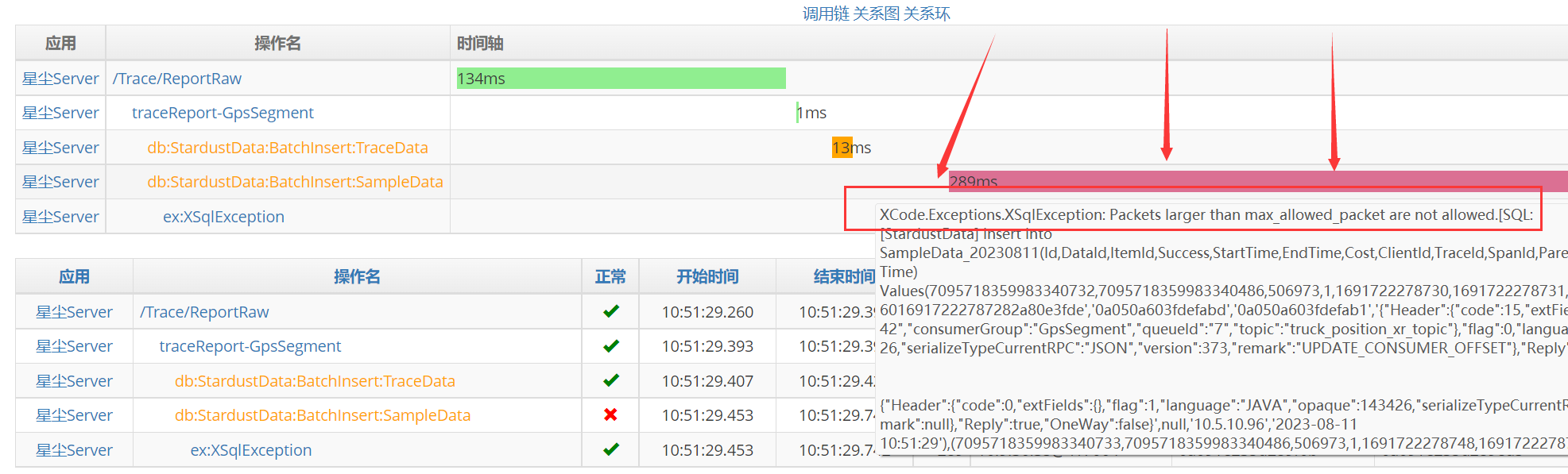
看到有sql错误,鼠标移上去,看见了错误内容“Packets larger than max_allowed_packet are not allowed”
至此,算是发现了问题所在。
埋点监控的Tag标签数据过大,批量插入MySql时,超过了最大数据包大小,导致落库失败!
星尘中该数据是异步落库,所以并不会导致接口报错,因此也没有告警提示。
找到问题以后,解决起来就容易多了。在星尘监控的应用跟踪器中,修改一下标签大小参数即可。

该参数默认值是1024,上个月为了分析问题修改为4096.
当然,也可以修改mysql配置,加大最大包大小参数。
两三分钟后,告警应用各埋点指标迅速上升,恢复到正常水平!
追本溯源
星尘在7月份增加了一项新功能,支持数据分表后进行行级压缩,埋点表和采样表存储空间占用空间一下子降低到原来的30%。
目前星尘存储30天压缩数据,每天2000万左右,总占用660G。如果没有压缩,将要占用2T以上。
正是因为空间富裕了,为了方便查找问题,才加大标签大小。
目前的星尘工作很健康,IO上压力比较大,虽然解决了空间占用问题,但是目前mysql仍然有着平均每秒12M字节的写入速度。