IOHelper主要是针对数据流Stream和字节数组Byte[]的扩展。
NewLife组件在二进制协议(包括通信协议和文件协议)上有极为深厚的积累和支持,完全依托于该扩展。各种协议包括但不限于:Http/Redis/Zip/SRMP/RocketMQ/MySql/Thrift/Hive
Nuget包:NewLife.Core
源码:https://github.com/NewLifeX/X/blob/master/NewLife.Core/IO/IOHelper.cs
视频:https://www.bilibili.com/video/BV1gq4y1g78w
视频:https://www.bilibili.com/video/BV1gm4y1A7h8
压缩与解压缩
Compress/Decompress 支持对数据流和字节数据进行压缩和解压缩,内置Deflate压缩算法;
CompressGZip/DecompressGZip 则是GZip压缩算法,适用于http压缩,或者单文件压缩;
数据流读写
ReadBytes
这是最常用的数据流扩展方法,从数据流中读取指定大小的字节数组,-1表示读取全部。
Byte[] ReadBytes(this Stream stream, Int64 length = -1)ToStr
数据流或字节数组转为字符串,支持指定编码,默认utf-8,常用于打日志
String ToStr(this Stream stream, Encoding encoding = null);
String ToStr(this Byte[] buf, Encoding encoding = null, Int32 offset = 0, Int32 count = -1);WriteArray/ReadArray
从数据流中读写字节数组,约定以7位压缩编码表示的长度为开头。这是通信协议中实现变长数据的常用手段。
Stream WriteArray(this Stream des, params Byte[] src);
Byte[] ReadArray(this Stream des);在通信协议中,字符串的传输也是先转为字节数组,然后采用该方法进行序列化。
WriteDateTime/ReadDateTime
从数据流中读写时间日期,约定4字节的Unix秒,也即是1970年以来秒数。
Stream WriteDateTime(this Stream stream, DateTime dt);
DateTime ReadDateTime(this Stream stream);字节数组与整数互转
这是二进制序列化基础,整数是最常用的一种数据类型
UInt16 ToUInt16(this Byte[] data, Int32 offset = 0, Boolean isLittleEndian = true);
UInt32 ToUInt32(this Byte[] data, Int32 offset = 0, Boolean isLittleEndian = true);
UInt64 ToUInt64(this Byte[] data, Int32 offset = 0, Boolean isLittleEndian = true);
Byte[] Write(this Byte[] data, UInt16 n, Int32 offset = 0, Boolean isLittleEndian = true);
Byte[] Write(this Byte[] data, UInt32 n, Int32 offset = 0, Boolean isLittleEndian = true);
Byte[] Write(this Byte[] data, UInt64 n, Int32 offset = 0, Boolean isLittleEndian = true);
Byte[] GetBytes(this UInt16 value, Boolean isLittleEndian = true);
Byte[] GetBytes(this Int16 value, Boolean isLittleEndian = true);
Byte[] GetBytes(this UInt32 value, Boolean isLittleEndian = true);
Byte[] GetBytes(this Int32 value, Boolean isLittleEndian = true);
Byte[] GetBytes(this UInt64 value, Boolean isLittleEndian = true);
Byte[] GetBytes(this Int64 value, Boolean isLittleEndian = true);以上扩展实现了从字节数组读取整数、向字节数组写入整数、把整数转为字节数组。
其中最亮眼的莫过于isLittleEndian,这是小端字节序,简称小字节序,相对而言,还有大端字节序。
在计算机内存和网络数据流中,数据都是以字节形式存在,一个整数Int32占用4个字节,谁在前面谁在后面呢?
通俗来讲,小端字节序就是整数较小部分放在前面,例如 0x12345678,在.net内存中应该是 [0x78, 0x56, 0x34, 0x12],因为.net是小端字节序,而0x78是这个整数最小的一个字节。
那么哪些场景是大端字节序呢?
已知,Java和Tcp/IP等一部网络协议,都是大端字节序,其它编程语言基本上都是小端字节序。ARM指令集比较特殊,不同芯片可能大小端混用。
因此,在日常开发中,如无例外,一般都是默认小端字节序,唯有开发网络协议时稍微注意一下。
字节序交换
在物联网领域,特别是工业物联网中,读取传感器数据时需要做16位交换或者32位交换。
典型场景有 ABCD / BADC / CDAB / DCBA,AB互换就是swap16,AB和CD互换是swap32。
Byte[] Swap(this Byte[] data, Boolean swap16, Boolean swap32);注:整数交换的完整版本,请参考 NewLife.IoT 组件
7位压缩编码整数
一个Int32整数,在内存中需要占用4个字节,但是绝大多数时候它很小,只有几十几百,占用的4个字节常常有两个是0x00,相当浪费。于是前辈们研究了各种整数压缩算法,例如Base 128 Varints和ZigZag等。这些算法想读懂不容易,感兴趣的同学自己去研究,我们这里只讲解最简单的一种。
整数0x12的二进制形式 0b0001_0010,最高位为0,在压缩算法中只需要1个字节,表示为 0b0001_0010;
整数0x1234的二进制形式 0b0001_0010_0011_0100,最高位为0,只需要2个字节,表示为 0b0010_0100_1011_0100;
因此,7位压缩编码整数的原理就是用7位表示数字,最高位表示下一个字节是否还有数据。从而得到,小于128的数字,只需要1个字节保存,小于等于0x3FFF=16383的整数,需要2个字节保存。
可用扩展如下:
Int32 ReadEncodedInt(this Stream stream);
UInt64 ReadEncodedInt64(this Stream stream);
Stream WriteEncodedInt(this Stream stream, Int64 value);
Byte[] GetEncodedInt(Int64 value);随着计算机内存和网络带宽的扩大,压缩整数的使用场景越来越少。
我的项目里面,曾经把100亿行数据放入一台Redis机器,占用360G内存,最重要的就是压缩整数!
十六进制编码
为了方便Http传输或数据库保存小量字节数据,常常采用十六进制编码(HEX编码)。
String ToHex(this Byte[] data, Int32 offset = 0, Int32 count = -1);
String ToHex(this Byte[] data, String separate, Int32 groupSize = 0, Int32 maxLength = -1);
Byte[] ToHex(this String data, Int32 startIndex = 0, Int32 length = -1);同时,也支持HEX字符串转为字节数组。
BASE64编码
传输和存储中小量字节数据,用BASE64更合适
String ToBase64(this Byte[] data, Int32 offset = 0, Int32 count = -1, Boolean lineBreak = false);
String ToUrlBase64(this Byte[] data, Int32 offset = 0, Int32 count = -1);
Byte[] ToBase64(this String data);但是在Http中使用Base64一定要小心,某些符号不支持拼接url,因此才有ToUrlBase64,特殊处理了不支持的字符。
HEX编码和Base64编码可参考码神工具,加密解密。
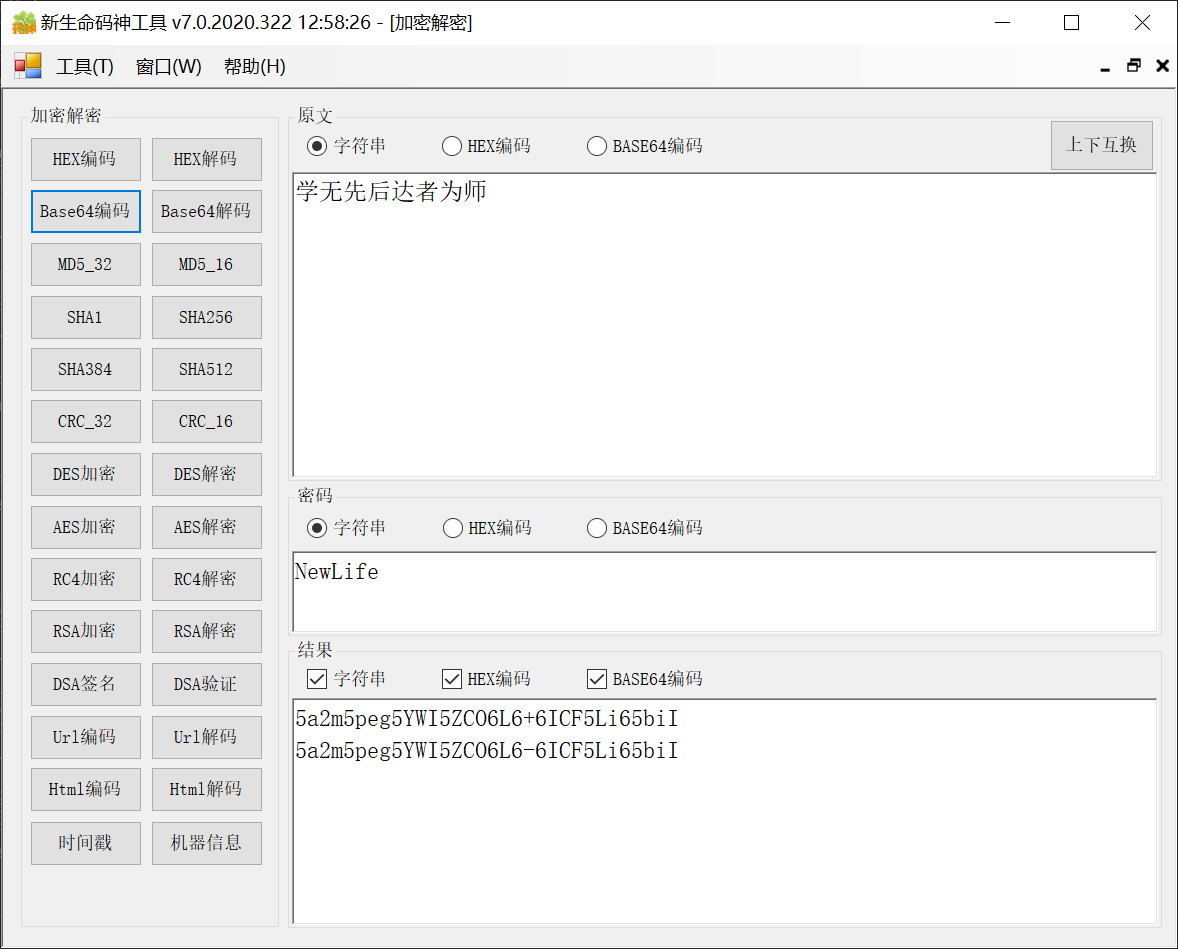
上图看到,Base64编码后,得到两个字符串,下面一个就是UrlBase64,避开了加号。
字节数据搜索
常用字符串搜索IndexOf,但是有时候要在一个字节数据流内搜索目标字符串,例如解析Http请求头中表单Post数据时需要查找分隔符。
内部提供了 Boyer Moore 算法实现,具体算法原理这里不展开,理论上最好的情况下可以做到O(n)。而传统的窗口滑动搜索,算法复杂度一般是O(m*n)。
/// <summary>Boyer Moore 字符串搜索算法,比KMP更快,常用于IDE工具的查找</summary>
/// <param name="source"></param>
/// <param name="pattern"></param>
/// <param name="offset"></param>
/// <param name="count"></param>
/// <returns></returns>
public static Int32 IndexOf(this Byte[] source, Byte[] pattern, Int32 offset = 0, Int32 count = -1)IndexOf 以扩展方法形式提供,在source中搜索pattern,从offset开始搜索,最多找count个字节。
准备一个超大字节数据,尝试在其中搜索目标字符串,可以体验到不一般的性能提升:
[Fact]
public void IndexOf()
{
var d = "------WebKitFormBoundary3ZXeqQWNjAzojVR7".GetBytes();
var buf = new Byte[8 * 1024 * 1024];
buf.Write(7 * 1024 * 1024, d);
var p = buf.IndexOf(d);
Assert.Equal(7 * 1024 * 1024, p);
p = buf.IndexOf(d, 7 * 1024 * 1024 - 1);
Assert.Equal(7 * 1024 * 1024, p);
p = buf.IndexOf(d, 7 * 1024 * 1024 + 1);
Assert.Equal(-1, p);
}
private static readonly Byte[] NewLine2 = new[] { (Byte)'\r', (Byte)'\n', (Byte)'\r', (Byte)'\n' };
[Fact]
public void IndexOf2()
{
var str = "Content-Disposition: form-data; name=\"name\"\r\n\r\n大石头";
var buf = str.GetBytes();
var p = buf.IndexOf("\r\n\r\n".GetBytes());
Assert.Equal(43, p);
p = buf.IndexOf(NewLine2);
Assert.Equal(43, p);
var pk = new Packet(buf);
var value = pk.Slice(p + 4).ToStr();
Assert.Equal("大石头", value);
}在 .NETCore3.0/.NET5.0 里,新增了 Span.IndexOf ,它有更好的性能,优先推荐使用。