雪花Id生成算法,是鼎鼎有名的分布式Id生成算法。它的优点在于,在分布式系统中快速生成有时间顺序的唯一编号!Snowflake实测每秒可生成900万个唯一Id。
Nuget包:NewLife.Core
源码:https://github.com/NewLifeX/X/blob/master/NewLife.Core/Data/Snowflake.cs
视频:https://www.bilibili.com/video/BV1yg411h77i
核心原理
使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,基本上保持自增。
格式:1bit保留 + 41bit时间戳 + 10bit机器 + 12bit序列号
第一位不使用,主要是为了避免部分场景变成负数;
41位时间戳,也就是2的41次方,毫秒为单位,足够保存69年。这里一般存储1970年以来的毫秒数,建议各个系统根据需要自定义这个开始日期;
10位机器码,理论上可以表示1024台机器,也可以拆分几位表示机房几位表示机器。这里默认采用本机IPv4地址最后两段以及进程Id一起作为机器码,确保机房内部不同机器,以及相同机器上的不同进程,拥有不同的机器码(非绝对,详细看下文);
12位序列号,表示范围0~4095,一直递增,即使毫秒数加一,这里也不会归零,避免被恶意用户轻易猜测得到前后订单号;
生成Id
务必保证 Snowflake 类的单例(每个业务模块一个实例),频繁多次实例化 Snowflake 可能导致重复!
NewId用于生成新的唯一Id
/// <summary>获取下一个Id</summary> /// <returns></returns> public virtual Int64 NewId(); /// <summary>获取指定时间的Id,带上节点和序列号。可用于根据业务时间构造插入Id</summary> /// <param name="time">时间</param> /// <returns></returns> public virtual Int64 NewId(DateTime time);
无参版默认使用当前时间生成唯一Id,也可以给指定时间生成唯一Id。
以下是采用雪花Id作为订单号。
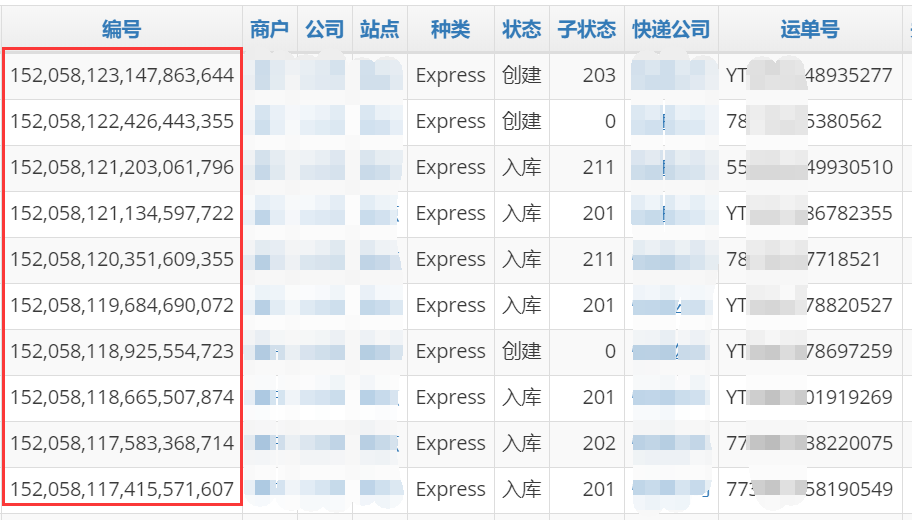
在物联网大数据领域,可能需要根据时间分表,此时适合使用NewId(time)重载,其中time使用客户端设备生成数据的时间。该方法在高速采集时需慎重使用,因为可能存在时间倒拨处理时暂停线程处理的问题。常见做法是雪花Id使用本地时间NewId(),也用该时间分表,而数据产生时间独立一个字段存储。
生成指定时间的Id
在物联网数据采集系统中,常常出现采集时间与入库时间不一致的问题,因为凑批上传或者网络波动等原因,一般采集后过一段时间才上传。如果物联网云平台在接收数据时使用本地时间生成雪花Id入库,那么就有可能当天采集的数据落入T+1的分表中(大数据存储一般分表),也不利于数据分析使用。
我们创造性实现了以下功能:
Int64 NewId(DateTime time, Int32 uid);
它可以根据指定时间和用户标识来生成雪花ID。此时使用采集时间作为第一个参数,传感器标识作为第二个参数。采集时间一般是毫秒级精度,在传感器标识唯一的情况下,可以确保雪花ID唯一。即使同一个毫秒内采集了一条以上数据,也可以采用Upsert机制入库,保留最后一条即可满足大多数使用场景。
解析Id
大型数据表,例如订单表、日志表等,可以使用Int64作为主键,然后使用雪花Id。因为雪花Id内带有时间戳信息,因此我们可以根据主键Id来直接搜索指定时间区间的数据。
/// <summary>时间转为Id,不带节点和序列号。可用于构建时间片段查询</summary> /// <param name="time">时间</param> /// <returns></returns> public virtual Int64 GetId(DateTime time);
GetId用于计算指定时间的基准Id,只有最高的时间部分,机器码和序列化为零。我们在计算指定时间区间(start, end)内的数据时,可以有:
Select * from Order where Id>=Get(start) and Id<GetId(end);
拿到一个雪花Id,也可以从中解析得到时间等信息
/// <summary>尝试分析</summary> /// <param name="id"></param> /// <param name="time">时间</param> /// <param name="workerId">节点</param> /// <param name="sequence">序列号</param> /// <returns></returns> public virtual Boolean TryParse(Int64 id, out DateTime time, out Int32 workerId, out Int32 sequence);
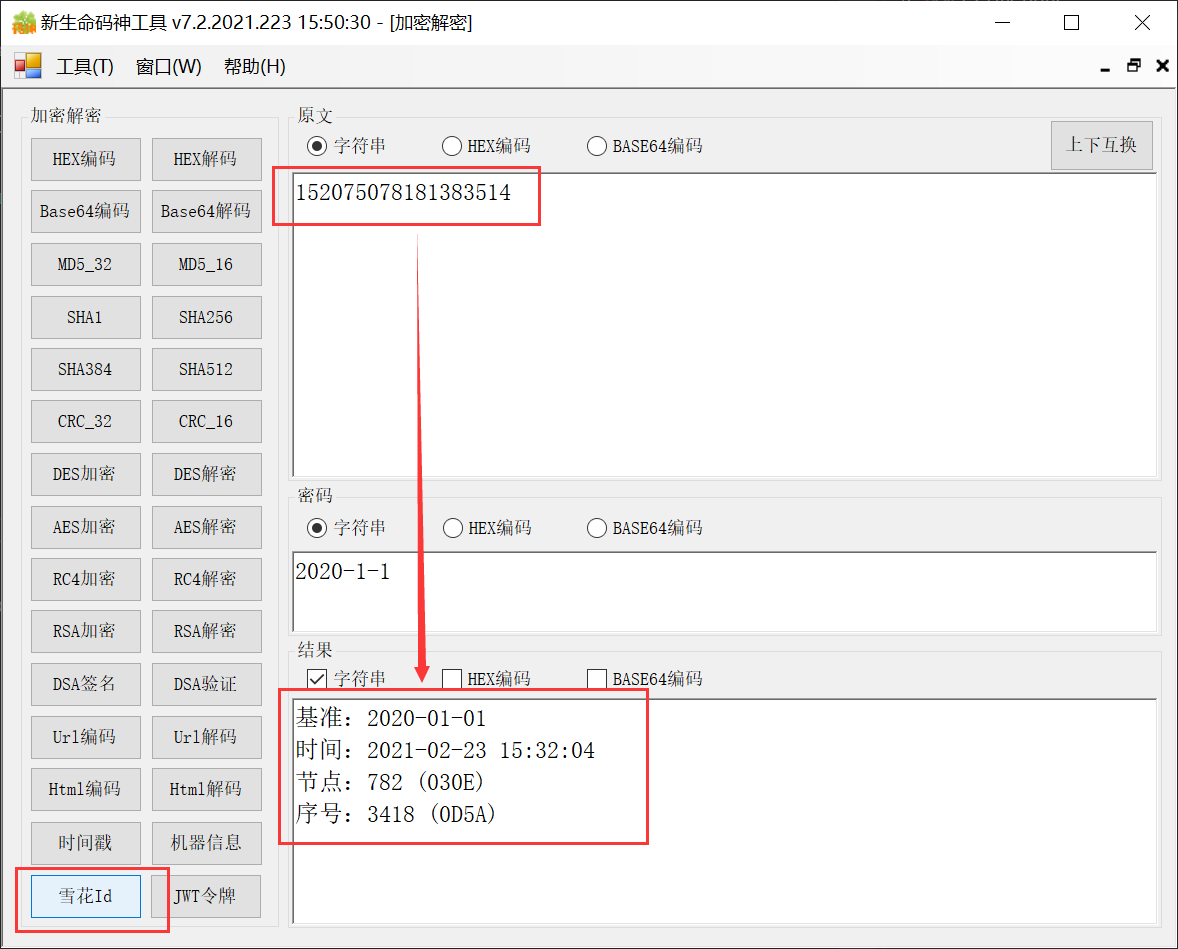
解析订单号 152075078181383514 ,时间基准设为 2020年1月1日
确保唯一性
由前文得知,雪花Id由毫秒时间戳、机器码和序号组成,其中毫秒时间戳和序号有可能碰撞,确保雪花Id唯一性的关键点就在于机器码。
Snowflake的机器码workerId默认由本机IP和进程Id计算得到,各取末尾5位移位后拼在一起。因此,局域网内不同机器,或者相同机器的不同进程,其机器码基本上不会相同。在多网段局域网,或者跨机房场景,机器码有一定可能性相同。机器码加入进程Id,避免某个应用在同一台服务器上多实例部署时得到相同workerId。如果要求绝对不相同的机器码,可通过手工设置唯一workerId的方式来实现。
在某台服务器某个应用实例进程里面,多个Snowflake实例默认共用了相同的workerId,因此可能生成相同的雪花Id。强烈要求各功能模块使用模块内的Snowflake单实例,以确保该功能模块内雪花Id的唯一性。如果不同模块的雪花Id也不能相同,可以让它们共用同一个Snowflake实例。
这里有同学要问,为什么不是干脆用一个10位随机数来作为workerId?这是一个相当好的问题,原因有下面几点:
- 10位随机数共有1024种可能,也就是说有千分之一的几率重复,特别是多次发版或重启后,碰撞到相同workerId的可能性加大;
- 在中小企业,机房不是特别大时,某个应用所在的若干台服务器,在本机IP上就能得到很好的唯一性,甚至可以人为干涉IP最后一段确保唯一,成本低,效果大;
绝对唯一
在中大型应用场景里,设置唯一机器码是确保雪花Id唯一性的最佳手段!
有的企业使用集中服务器来分配唯一机器码,有的企业通过Redis累加数来分配,这些是不同雪花Id实现方式的根本差别所在!
既然必须手工设置才能得到绝对唯一性,那么在中小场景里就可以采用性价比较高的方案。
本文的Snowflake支持配置Redis,使得机器码绝对唯一,从而确保所生成的雪花Id绝对唯一!
/// <summary>workerId分配集群。配置后可确保所有实例化的雪花对象得到唯一workerId,建议使用Redis</summary>
public static ICache Cluster { get; set; }
/// <summary>加入集群。由集群统一分配WorkerId,确保唯一,从而保证生成的雪花Id绝对唯一</summary>
/// <param name="cache"></param>
/// <param name="key"></param>
public virtual void JoinCluster(ICache cache, String key = "SnowflakeWorkerId")
{
var wid = (Int32)cache.Increment(key, 1);
WorkerId = wid & 0x3FF;
}使用时,只需要配置Cluster为Redis对象即可,例如:
var rds = new Redis("10.0.0.3:6379", "password", 0);
Snowflake.Cluster = rds;时钟倒拨问题
雪花算法的另一个难题就是时间倒拨,也就是跑了一段时间之后,系统时间回到过去。显然,时间戳上有很大几率产生相同毫秒数,在机器码workerId相同的情况下,有较大几率出现重复雪花Id。
Snowflake根据SmartOS操作系统调度算法,初始化时锁定基准时间,并记录处理器时钟嘀嗒数。在需要生成雪花Id时,取基准时间与当时处理器时钟嘀嗒数,计算得到时间戳。也就是说,在初始化之后,Snowflake根本不会读取系统时间,即使时间倒拨,也不影响雪花Id的生成!
总结
在分布式系统中,雪花Id具有非常重要的意义。星尘大量使用雪花Id,用于存储跟踪数据和采样数据,以前必须先插入跟踪数据得到自增Id然后才能插入采样数据(需要关联)的问题迎难而解,两者都可以同时走批量插入。
对于日志型数据表,强烈推荐使用雪花Id,因为它带有时间戳信息,等同于省去了CreateTime字段的索引。