NewLife.XCode是一个有10多年历史的开源数据中间件,支持nfx/netcore,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode。
整个系列教程会大量结合示例代码和运行日志来进行深入分析,蕴含多年开发经验于其中,代表作有百亿级大数据实时计算项目。
开源地址:https://github.com/NewLifeX/X (求star, 795+)
大数据投名状
先来看看“大数据演示平台”:http://bigdata.newlifex.com
SQLite单表4亿行订单数据,文件大小26.5G,阿里云1C1G的ECS服务器,由 NewLife.XCode + NewLife.Cube 驱动
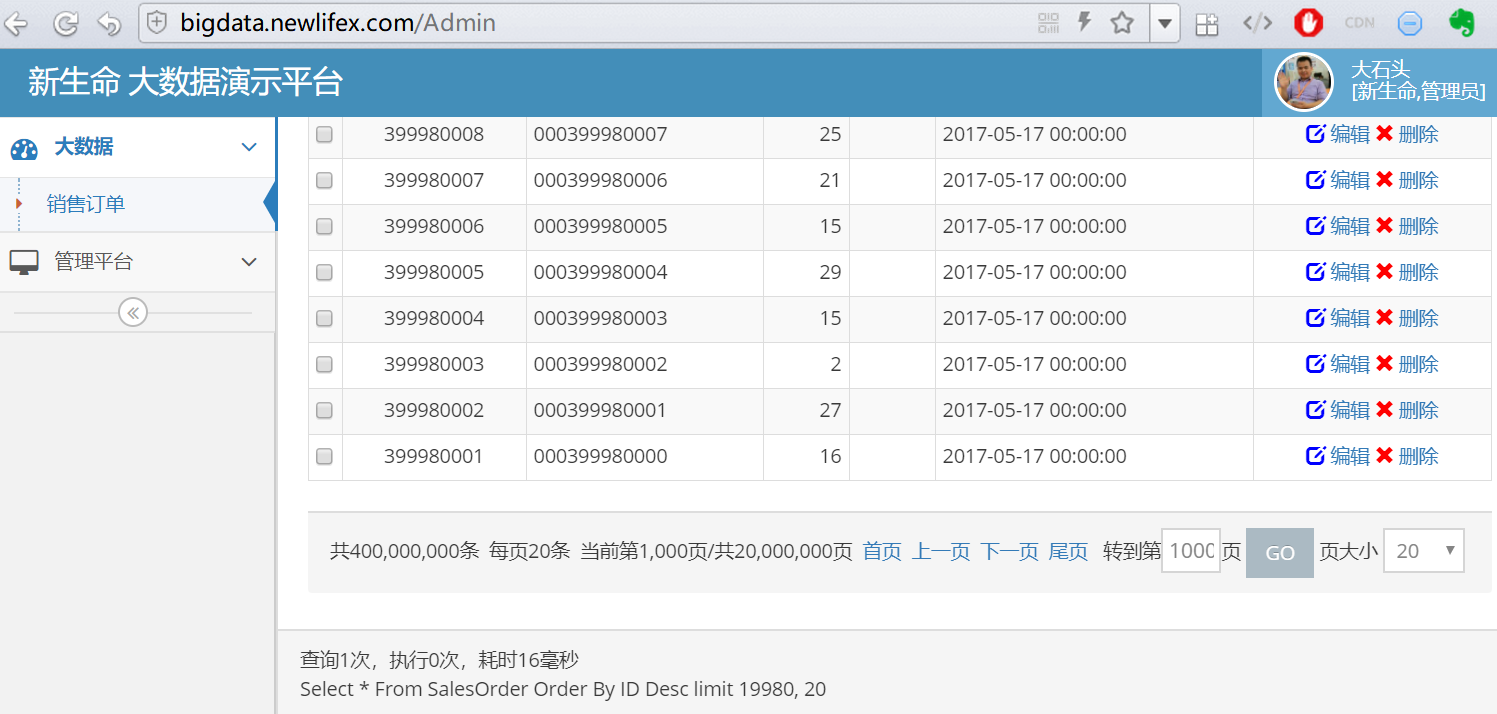
如上,在4亿行中查询第1000页,耗时16毫秒。
对于高手来说,这个算不得什么,只要注意好索引就行。
这个“演示平台”建立于两年前,给两家领先物流企业递交了简历,其中一家因SQLite拒绝了,另一家给了数据架构师!
现在,每天1亿个快递包裹在路上,产生大量扫描数据。单表数十亿数据很常见(Oracle按月分区),一款数据产品几亿明细数据比比皆是(MySql分表)。
代码之巅/天外飞仙
再来看一下各种数据库的极致性能,飞仙平台 http://feixian.newlifex.com

SQLite插入第一名 56万tps;
MySql插入第一名 60万tps;
SQLite查询(带缓存)1126万qps;
这是上百人用了各种机器(笔记本、台式机、服务器)调整参数进行大量测试后得到的性能排行榜!
所有测试,由 NewLife.XCode 支持!
实际应用中,即使能达到上述性能十分之一,亦能立于不败之地。有时候甚至还达不到百分之一。
尽管如此,极致性能的研究也给我们的应用方式以及数据库参数设置指明了方向!
索引完备
使用关系型数据库来做大数据,第一步必然是索引!
单表超过1000万数据,任何查询都必须走索引!否则数据库一定跟你说ByeBye!
前面SQLite单表4亿数据,共有两个索引,自增ID作为主键,另外有订单号索引。
大表索引不宜过多,务必以数据的主要使用方式来建立一两个即可,尽量不要超过三个,经索引过滤后的数据尽量控制住1万行以内。
常见大型表索引用法:
日志型
订单操作表、快递扫描表、传感数据表等超大日志型数据表,每日数千万到数亿行,只插入不修改,最重要的字段就是时间戳CreateTime,建立索引,同时可以按时间分区分表。
这种大表最常见用法就是根据时间戳去抽取来做业务处理,那就是鼎鼎大名的ETL。处理性能1000~10000tps
更高大上一点,就是抽取数据写入Kafka/RocketMQ,名正言顺进行大数据分析!处理性能10万tps
因工作需要,我们依据时间戳抽取了30天共100亿数据写入Redis,供100+应用进行实时数据分析。处理性能100万tps
抽取数据时以每批次抽取5000~20000行为宜,依次调整查询时间段,重量级蚂蚁调度系统(https://github.com/NewLifeX/AntJob)具备动态步进抽取能力,可自动调节最优抽取间隔。
总结起来一句话:按时间戳轮数据!
状态表
订单运单都是有状态数据,在整个生命周期中,状态会多次改变。许多业务往往要求两个或多个状态相匹配,那就要求有一张庞大的状态表。
状态表最合适的主键就是订单号,并且一般分表分库存储,常见分表公式 Crc16(code)%1024,分表数以单表不超过1000万为宜。
使用1024状态表的数据库一般是分布式玩法,比较合适分8库,每个库128表,很多应用服务器各司其职,大家共同操作一张表的几率大减。
统计分析表
统计表主键一般由统计日期和分类构成,为了方便可建立字符串ID主键,由 {date}_{cid} 组成,也可以对 date + cid 两个字段建立唯一联合索引。
之所以建立 {date}_{cid} 的ID主键,主要是为了方便写明细数据,无需等待统计表插入后(假如使用自增)才得到统计ID。
明细表一定必须根据统计ID来查,由统计ID跟其它主要业务字段构成主索引。
合理查询
既然有了索引,那么大表的任意查询都必须命中索引(或者部分使用索引) 。
为了索引,为了降低数据库负担,有时候宁可多查一点,先把数据查出来,再在内存里面做二次处理!
大数据的瓶颈一定是数据库,应用服务器往往性能过剩!
因此,完全可以把一部分“计算”由数据库转移到应用服务器之中来进行处理。
大表少用join关联,宁可多次查询;
字段精炼
常听到许多人说每天处理数据多少多少TB/PB,听起来数据分析还可以论斤称?挺尴尬的!
虽然数据库很容易遇到IO瓶颈,但很多人达不到那一步。
数据容量上的优化空间还是极大的。
大表字段精简原则:
- 能存ID就别存Name。经常见到用户、商家、地区等信息,又存ID又存Name,甚至还存一个Code。此时需要XCode的扩展属性
- 适当冗余。为了便于查询,可以适当冗余一些字段,但绝不能滥用。比如商家所在地区,如果查询用不到而只是分析时使用,就不需要保存商家ID以外还保存地区
- 只查询需要的字段。这一点跟XCode推崇 select * 并不相悖,绝大部分百万级以内小表可以这么干,但是千万亿万级大表则需按需查询了。
充分利用缓存
少用join关联,慎用字段冗余,即可大量发挥XCode的缓存优势。
10万乃至100万维表数据可尽量缓存起来,随时配合亿万级大表进行数据分析。
另一方面就是数据库缓存,需要DBA大力支持!