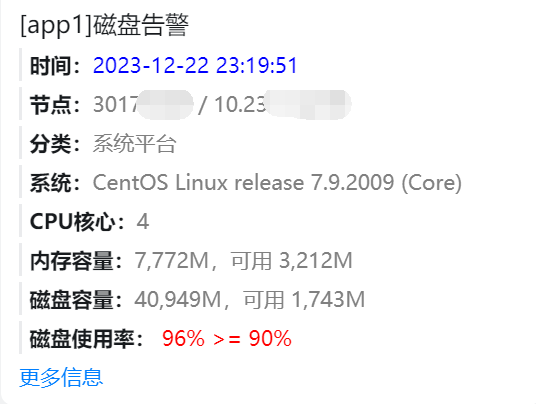
客户反馈,收到某台服务器的磁盘告警。经查,该告警由星尘节点监控发出,而该服务器也正是星尘所在服务器。
分析问题
ssh登录服务器,使用命令检查哪个目录占用空间较大,逐个目录执行:
du -sh *最终发现,星尘所在目录`/root/star/Data`中的StardustData.db,文件达到27G。
这里需要补充一下,客户部署IoT平台应用,仅用到2台服务器,一台部署星尘,一台部署IoT平台。为了节省资源,星尘直接使用sqlite,把mysql资源全部留给IoT平台。因为星尘的数据没有那么重要,即使损坏丢失也不影响IoT平台业务的正常运营。
检查星尘平台设置,保留数据时间都设置得很小,不大可能是数据过多所导致的问题。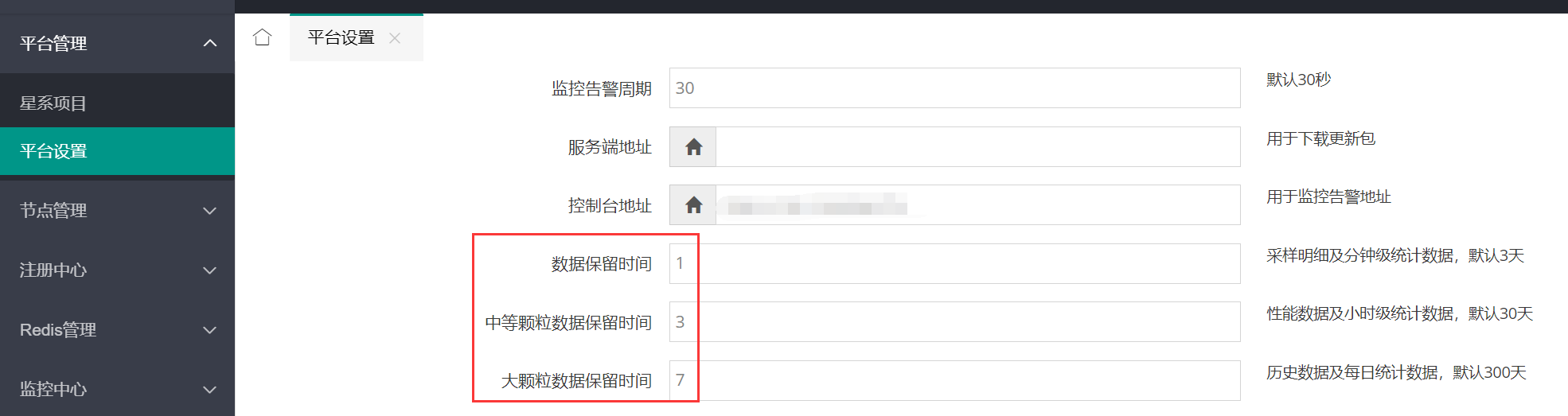
在服务器上执行 sqlite3 StardustData.db,检查表确认,的确只保留了昨天和今天的数据。星尘会根据上图配置,定时清理数据,对于分表的数据直接drop过期表,非分表数据,每10分钟delete一次。从监控调用链来看,删除数据也是正常执行。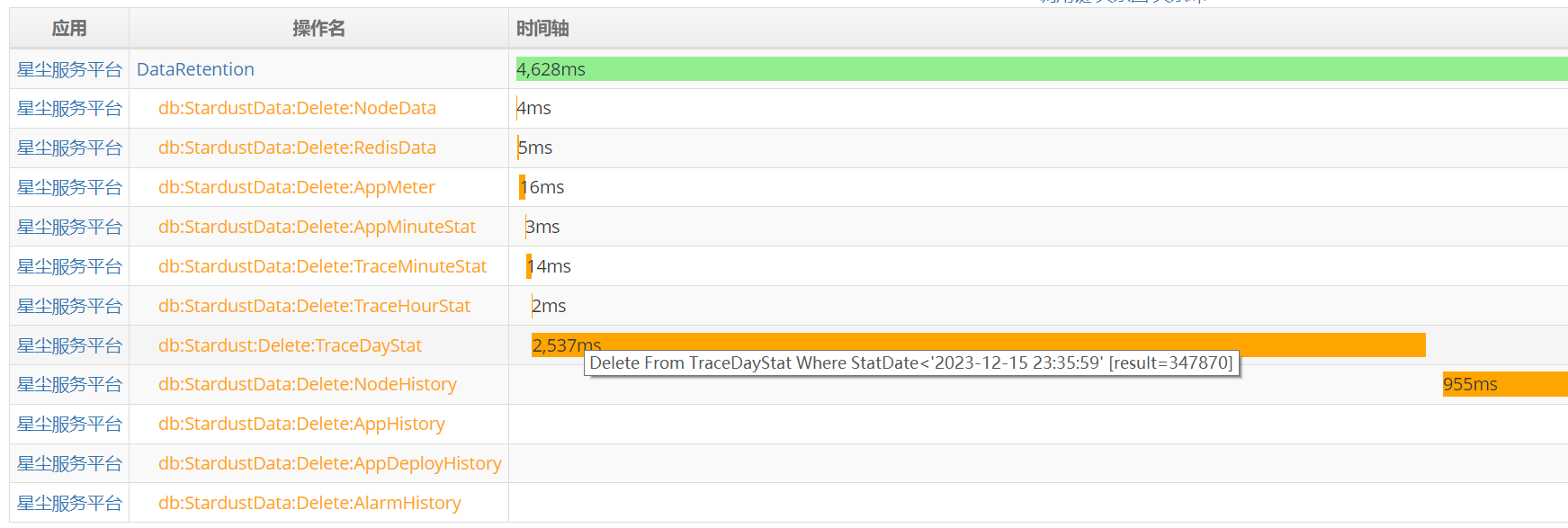
那么几乎可以确认,这是sqlite的问题,几百万行数据不应该占用27G。
虽然StardustData不是特别重要的数据,但是能留下来总比丢弃掉要好一些,尽力吧!
注:星尘重要数据保存在连接名Stardust中,对应sqlite数据库Stardust.db。一般使用mysql时,会让Stardust和StardstData这两个连接名共用一个mysql数据库。
解决问题
尝试收缩数据库,在sqlite3里面执行VACUUM命令,等了几分钟后提示错误,磁盘已满。原来,磁盘可用空间只剩下1.7G了。此路不通!
尝试备份数据库,在sqlite3里面执行 .backup sd.db,等了几分钟后提示错误,磁盘已满。不用看也知道,1.7G空间根本不足以执行这些命令。
这个库有27G大小,下载回来进行收缩处理很不现实,需要想办法在线处理。
想起2012年客户SCM系统sqlite数据库损坏时,(那会在祁连雪山里,后来到西宁上网吧去),我的处理方法:把数据库导出到sql文件,修改事务回滚语句后,重新导入到新库。
我们这个数据库是完好的,应该不需要修改,直接导出导入即可。
sqlite3 StardustData.db .dump > aa.sql
sqlite3 sd.db < aa.sql
mv StardustData.db StardustData.db.231223
cp sd.db StardustData.db关闭星尘服务,执行'systemctl stop StarAgent',其实就是关闭星尘代理,自动停止本机所有应用。执行结果:
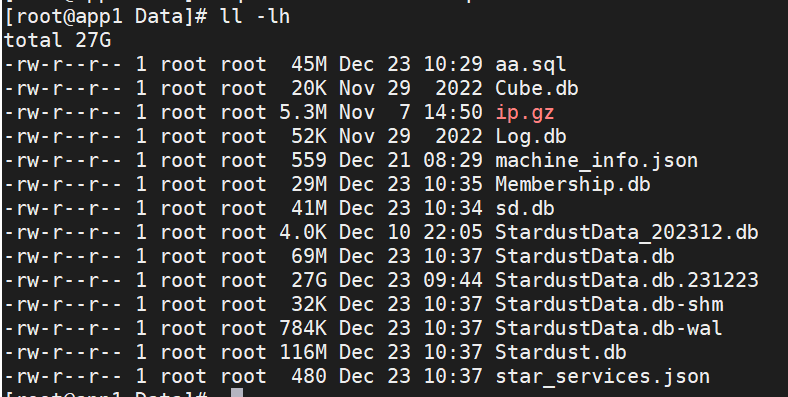
导出sql后,发现sql文件只有45M,那么最终数据库大概率应该比这个要小。因此决定暂时不要删除27G这个文件,以免操作失误。
导入sql到新库sd.db,并拷贝一份成为StardustData.db。
重新启动星尘代理,启动星尘服务,数据检查一切正常!
最后删掉备份文件,全面释放磁盘空间。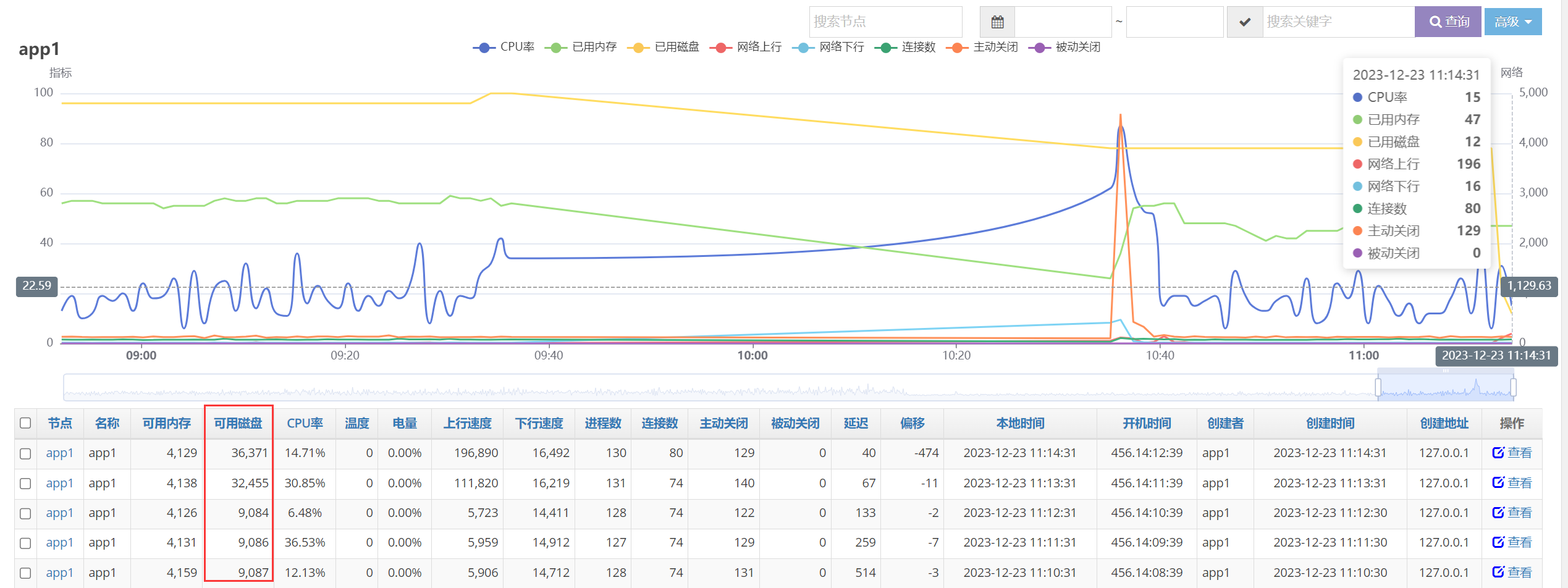
星尘节点监控显示,磁盘已经释放。上图9:30~10:30之间数据缺失,没错,这就是我们关闭了这台服务器StarAgent,分析解决问题的那一个小时。
而应用层面的监控数据是不受影响的,在服务器不可用时,各应用在内存里面保留埋点数据最长2小时。等到服务器或网络恢复后马上上报,下图就是10点多的埋点在10:35上传: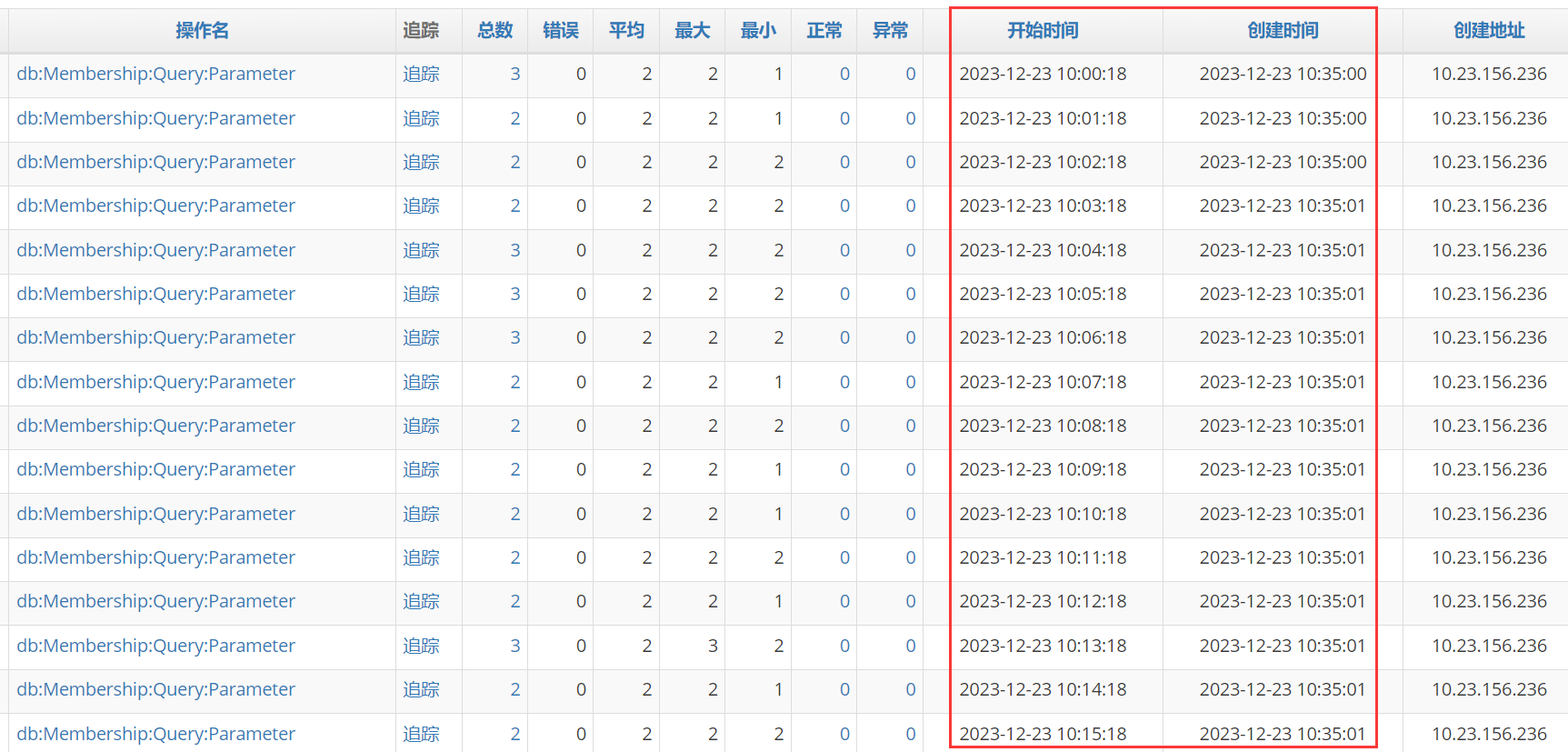
总结
sqlite数据库长时间运行后,可能有许多冗余空间无法收缩。
sqlite的数据收缩和备份,需要很大的磁盘空间,可通过导出导入sql来解决。