NewLife.XCode是一个有15年历史的开源数据中间件,支持netcore/net45/net40,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode。
整个系列教程会大量结合示例代码和运行日志来进行深入分析,蕴含多年开发经验于其中,代表作有百亿级大数据实时计算项目。
开源地址:https://github.com/NewLifeX/X (求star, 938+)
XCode是重度充血模型,以单表操作为核心,不支持多表关联Join,复杂查询只能在where上做文章,整个select语句一定是from单表,因此对分表操作具有天然优势!
!! 阅读本文之前,建议回顾《百亿级性能(索引的威力)》,其中“索引完备”章节详细描述了大型数据表的核心要点。
100亿数据其实并不多,一个比较常见的数据分表分库模型:
MySql数据库8主8从,每服务器8个库,每个库16张表,共1024张表(从库也有1024张表) ,每张表1000万到5000万数据,整好100亿到500亿数据!
全自动分表
通过配置自动分表策略 Meta.ShardPolicy ,添删改查自动找到正确的表,业务代码无感。
在星尘监控中,埋点采样数据非常多,需要按天分表,于是在采样数据实体类的静态构造函数中配置分表策略。除此之外,使用该实体类的业务代码把它当做单表来用即可。(例子来自于星尘Stardust监控中心的采样数据,按天分表)
static SampleData()
{
// 配置自动分表策略,一般在实体类静态构造函数中配置
Meta.ShardPolicy = new TimeShardPolicy(nameof(Id), Meta.Factory)
{
ConnPolicy = "{0}",
TablePolicy = "{0}_{1:yyyyMMdd}",
Step = TimeSpan.FromDays(1),
};
}自动分表策略使用时间分表(也可以是自定义的其它策略),该策略指定雪花Id字段作为分表依据。连接策略(分库)和表策略规则中,{0}表示默认名称(如表名默认SampleData),{1}参数就是时间,这里取年月日,构成一个标准的按天分表。分表时间字段一般使用雪花Id或者创建时间CreateTime。
众所周知,雪花Id里面含有时间信息(毫秒),我们来看看自动分表的几种应用场景:
- 添加。从主键雪花Id中解析得到时间,再根据时间策略计算得到表名,生成Insert语句;
- 删除。从主键雪花Id中解析得到时间,再根据时间策略计算得到表名,生成Delete语句;
- 修改。从雪花Id得知时间,结合策略得到表名,生成Update语句;
- 单查。从雪花Id得知时间,结合策略得到表名,生成Select查询语句;
- 批查。必须带有时间范围,并且使用WhereExpression表达式,否则直接抛出异常。从表达式中找到时间区间,结合策略得到多个表名,依次执行查询,直到满足分页行数为止;
添删改查比较容易理解,来看一下批量查询的例子(来自于物联网平台NewLife.IoT的设备数据,按天分表):
public static IList<DeviceData> Search(Int32 deviceId, String topics, DateTime start, DateTime end, String key, PageParameter page)
{
var exp = new WhereExpression();
if (deviceId >= 0) exp &= _.DeviceId == deviceId;
if (!topics.IsNullOrEmpty()) exp &= _.Topic.In(topics.Split(","));
exp &= _.Id.Between(start, end, Meta.Factory.Snow);
if (!key.IsNullOrEmpty()) exp &= _.Topic.Contains(key) | _.Data.Contains(key) | _.Creator.Contains(key) | _.CreateIP.Contains(key);
return FindAll(exp, page);
}这里的 _.Id.Between(start, end, Meta.Factory.Snow) 就是按照雪花Id查询落入某个时间区间的数据,时间区间有可能覆盖多天,底层将会每个表都查一次,直到满足一页行数为止。
Tips:全自动用主键字段分表时,不能启用自增
<Column Name="ID" DataType="Int64" PrimaryKey="True" Description="编号" />实体Biz启用分表
// 分表分库
Meta.ShardPolicy = new TimeShardPolicy(nameof(ID), Meta.Factory)
{
//ConnPolicy = "{0}",
TablePolicy = "{0}_{1:yyyyMMdd}",
Step = TimeSpan.FromDays(1),
Field = _.ID
};魔方通用查询ReadOnlyEntityController.cs
/// <summary>搜索数据集</summary>
/// <param name="p"></param>
/// <returns></returns>
protected virtual IEnumerable<TEntity> Search(Pager p)
{
var start = p["dtStart"];
var end = p["dtEnd"];
var act = Request.Path.ToUriComponent();
var key = p["q"];
var filterSos = p["filterSos"];
var whereExpression = Entity<TEntity>.SearchWhereByKeys(key);
#region 时间查询
var findTime = Entity<TEntity>.Meta.Factory.AllFields.Find(x =>
{
if (act.IndexOf("User") == -1)
{
return x.Field.ColumnName.Equals("CreateTime");
}
else
{
return x.Field.ColumnName.Equals("RegisterTime");
}
});
if (findTime == null)
findTime = Entity<TEntity>.Meta.Factory.MasterTime;
if (findTime != null)
{
var startTime = start != null ? start.ToDateTime().ToString("yyyy-MM-dd 00:00:00").ToDateTime(): DateTime.Now.Date;
var endTime = end != null ? end.ToDateTime(): DateTime.Now;
var shardPolicy = Entity<TEntity>.Meta.ShardPolicy as TimeShardPolicy;
if (shardPolicy != null)
{
if(shardPolicy.Field!=null)
whereExpression &= shardPolicy.Field.Between(startTime, endTime, Entity<TEntity>.Meta.Factory.Snow);
else
whereExpression &= Entity<TEntity>.Meta.Factory.Unique.Between(startTime, endTime, Entity<TEntity>.Meta.Factory.Snow);
}
else
whereExpression &= findTime.Between(startTime, endTime);
}
#endregion
// 根据模型列设置,拼接作为搜索字段的字段
var modelTable = ModelTable;
var modelCols = modelTable?.GetColumns()?.Where(w => w.ShowInSearch)?.ToList() ?? new List<ModelColumn>();
foreach (var col in modelCols)
{
var val = p[col.Name];
if (val.IsNullOrWhiteSpace()) continue;
var fields = Entity<TEntity>.Meta.Table.FindByName(col.Name);
if (!(fields is null)) whereExpression &= fields == val;
}
//添加映射字段查询
foreach (var item in Entity<TEntity>.Meta.Factory.Fields)
{
var val = p[item.Name];
if (!val.IsNullOrWhiteSpace())
{
whereExpression &= item.Equal(val);
}
}
return Entity<TEntity>.FindAll(whereExpression, p);
}分表后Meta.Session.Count会变为0,需要手动注释biz文件下的代码,并重写使用到的FindAll、Find
// 实体缓存
//if (Meta.Session.Count < 1000) return Meta.Cache.Find(e => e.ID == id);半自动分表
使用自动分表策略,有时候并不知道要查的数据在哪一天,只能指定一个比较大的范围,希望从新往旧倒过来查询,只要在某一天查到数据即停止向前继续查。这就需要用到 Meta.AutoShard 方法,还得把开始结束时间倒过来传进去。(例子来自于星尘Stardust监控中心的采样数据,按天分表)
public static IList<SampleData> Search(Int64 dataId, String traceId, DateTime start, DateTime end, PageParameter page)
{
var exp = new WhereExpression();
if (dataId > 0) exp &= _.DataId == dataId;
if (!traceId.IsNullOrEmpty()) exp &= _.TraceId == traceId;
// 时间区间倒序,为了从后往前查
return Meta.AutoShard(end.AddSeconds(1), start, () => FindAll(exp, page))
.FirstOrDefault(e => e.Count > 0) ?? new List<SampleData>();
}手工分表
使用自动分表策略,有时候需要非常复杂的查询逻辑,但能从中得到目标数据所在时间点,可以使用 Meta.CreateShard 手工分表。(例子来自于星尘Stardust监控中心的采样数据,按天分表)
public static IList<TraceData> Search(Int32 appId, Int32 itemId, String clientId, String name, String kind, Int32 minError, DateTime start,DateTime end, String key, PageParameter page)
{
var exp = new WhereExpression();
if (appId >= 0) exp &= _.AppId == appId;
if (itemId > 0) exp &= _.ItemId == itemId;
if (!clientId.IsNullOrEmpty()) exp &= _.ClientId == clientId;
if (!name.IsNullOrEmpty()) exp &= _.Name == name;
if (!key.IsNullOrEmpty()) exp &= _.ClientId == key | _.Name == key;
if (minError > 0) exp &= _.Errors >= minError;
if (appId > 0 && start.Year > 2000)
{
var fi = kind switch
{
"day" => _.StatDate,
"hour" => _.StatHour,
"minute" => _.StatMinute,
_ => _.StatDate,
};
if (start == end)
exp &= fi == start;
else
exp &= fi.Between(start, end);
}
else
exp &= _.Id.Between(start, end, Meta.Factory.Snow);
using var split = Meta.CreateShard(start);
return FindAll(exp, page);
}分表原理
实体操作时并不涉及表名和连接名,仅在执行数据库操作构造添删改查SQL语句时,从上下文中取得表名。因此,分表分库原理就是在业务代码(包含实体操作)之前,改变上下文中的表名和连接名。
原始分表写法如下:
History.Meta.ConnName = $"HDB_{i + 1}";
History.Meta.TableName = $"History_{j + 1}";只是这样实在太啰嗦了,在业务代码之后还得把ConnName/Table恢复为原值(否则其它代码有可能用到这个线程上下文)。并且考虑到异常发生的情况,还得加上try-finally
History.Meta.ConnName = $"HDB_{i + 1}";
History.Meta.TableName = $"History_{j + 1}";
try{
// todo 业务代码
}finally{
History.Meta.ConnName = null;
History.Meta.TableName = null;
}这里强烈推荐新用法,退出作用域后自动还原,再也不用考虑置空和异常
using var split = History.Meta.CreateSplit($"HDB_{i + 1}", $"History_{j + 1}");
// todo 业务代码例程剖析
(下文开始编写于2018年,以下分表用法比较老,XCode仍然支持,仅供理论参考。建议使用新方法,20220507注)
例程位置:https://github.com/NewLifeX/X/tree/master/Samples/SplitTableOrDatabase
新建控制台项目,nuget引用NewLife.XCode后,建立一个实体模型(修改Model.xml):
<Tables Version="9.12.7136.19046" NameSpace="STOD.Entity" ConnName="STOD" Output="" BaseClass="Entity" xmlns:xs="http://www.w3.org/2001/XMLSchema-instance" xs:schemaLocation="http://www.newlifex.com https://raw.githubusercontent.com/NewLifeX/X/master/XCode/ModelSchema.xsd" xmlns="http://www.newlifex.com/ModelSchema.xsd">
<Table Name="History" Description="历史">
<Columns>
<Column Name="ID" DataType="Int32" Identity="True" PrimaryKey="True" Description="编号" />
<Column Name="Category" DataType="String" Description="类别" />
<Column Name="Action" DataType="String" Description="操作" />
<Column Name="UserName" DataType="String" Description="用户名" />
<Column Name="CreateUserID" DataType="Int32" Description="用户编号" />
<Column Name="CreateIP" DataType="String" Description="IP地址" />
<Column Name="CreateTime" DataType="DateTime" Description="时间" />
<Column Name="Remark" DataType="String" Length="500" Description="详细信息" />
</Columns>
<Indexes>
<Index Columns="CreateTime" />
</Indexes>
</Table>
</Tables>在Build.tt上右键运行自定义工具,生成实体类“历史.cs”和“历史.Biz.cs”。不用修改其中代码,待会我们将借助该实体类来演示分表分库用法。
为了方便,我们将使用SQLite数据库,因此不需要配置任何数据库连接,XCode检测到没有名为STOD的连接字符串时,将默认使用SQLite。
此外,也可以通过指定名为STOD的连接字符串,使用其它非SQLite数据库。
按数字散列分表分库
大量订单、用户等信息,可采用crc16散列分表,我们把该实体数据拆分到4个库共16张表里面:
static void TestByNumber()
{
XTrace.WriteLine("按数字分表分库");
// 预先准备好各个库的连接字符串,动态增加,也可以在配置文件写好
for (var i = 0; i < 4; i++)
{
var connName = $"HDB_{i + 1}";
DAL.AddConnStr(connName, $"data source=numberData\\{connName}.db", null, "sqlite");
History.Meta.ConnName = connName;
// 每库建立4张表。这一步不是必须的,首次读写数据时也会创建
//for (var j = 0; j < 4; j++)
//{
// History.Meta.TableName = $"History_{j + 1}";
// // 初始化数据表
// History.Meta.Session.InitData();
//}
}
//!!! 写入数据测试
// 4个库
for (var i = 0; i < 4; i++)
{
var connName = $"HDB_{i + 1}";
History.Meta.ConnName = connName;
// 每库4张表
for (var j = 0; j < 4; j++)
{
History.Meta.TableName = $"History_{j + 1}";
// 插入一批数据
var list = new List<History>();
for (var n = 0; n < 1000; n++)
{
var entity = new History
{
Category = "交易",
Action = "转账",
CreateUserID = 1234,
CreateTime = DateTime.Now,
Remark = $"[{Rand.NextString(6)}]向[{Rand.NextString(6)}]转账[¥{Rand.Next(1_000_000) / 100d}]"
};
list.Add(entity);
}
// 批量插入。两种写法等价
//list.BatchInsert();
list.Insert(true);
// 恢复默认
History.Meta.TableName = null;
}
// 恢复默认
History.Meta.ConnName = null;
}
}通过 DAL.AddConnStr 动态向系统注册连接字符串:
var connName = $"HDB_{i + 1}";
DAL.AddConnStr(connName, $"data source=numberData\\{connName}.db", null, "sqlite");连接名必须唯一,且有规律,后面要用到。数据库名最好也有一定规律。
使用时通过Meta.ConnName指定后续操作的连接名,Meta.TableName指定后续操作的表名,本线程有效,不会干涉其它线程。
var connName = $"HDB_{i + 1}";
History.Meta.ConnName = connName;
History.Meta.TableName = $"History_{j + 1}";注意,ConnName/TableName改变后,将会一直维持该参数,直到修改为新的连接名和表名。
指定表名连接名后,即可在本线程内持续使用,后面使用批量插入技术,给每张表插入一批数据。
数据操作完成后,通过给ConnName/TableName置空,恢复默认值。
运行效果如下:
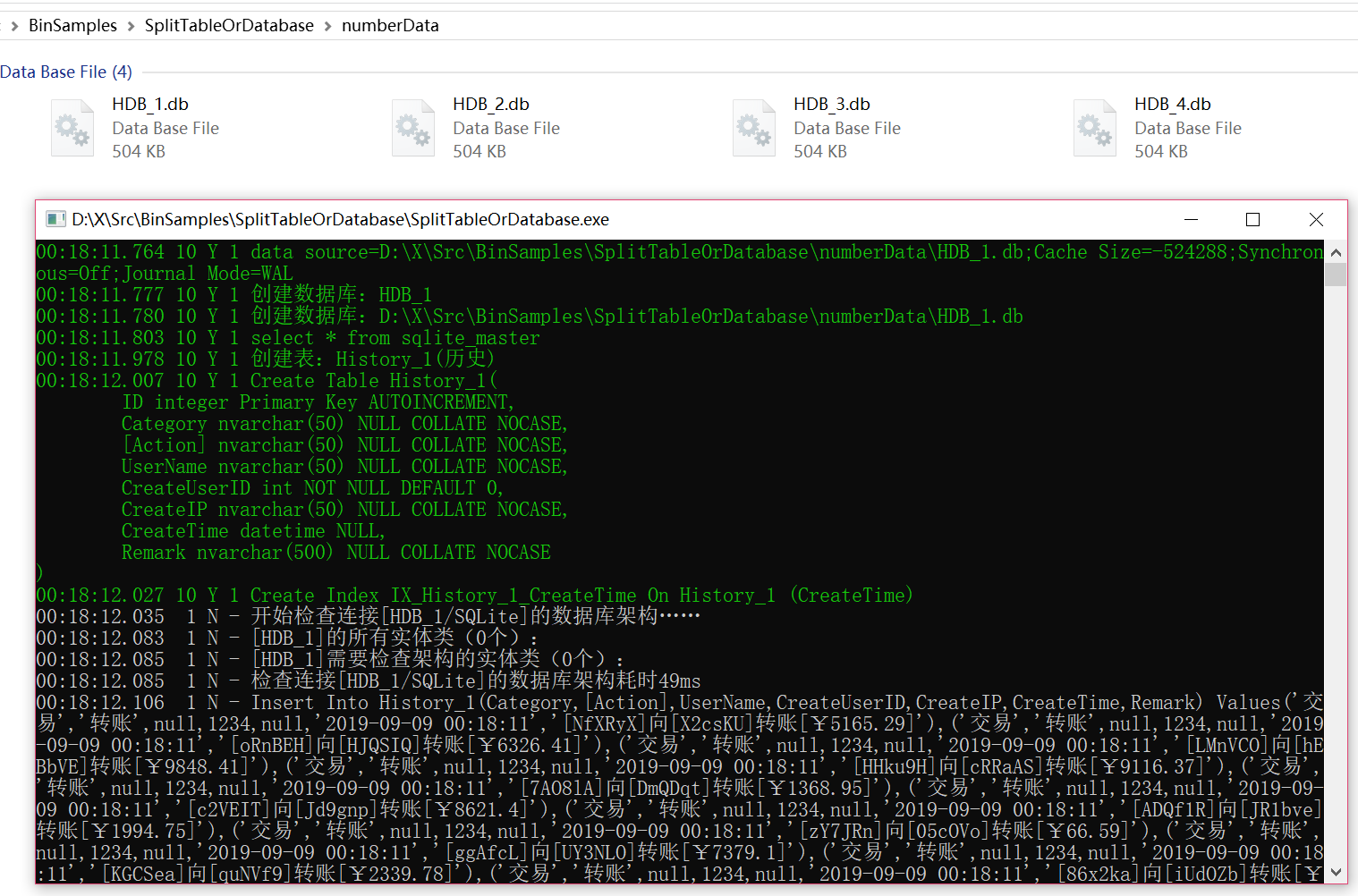
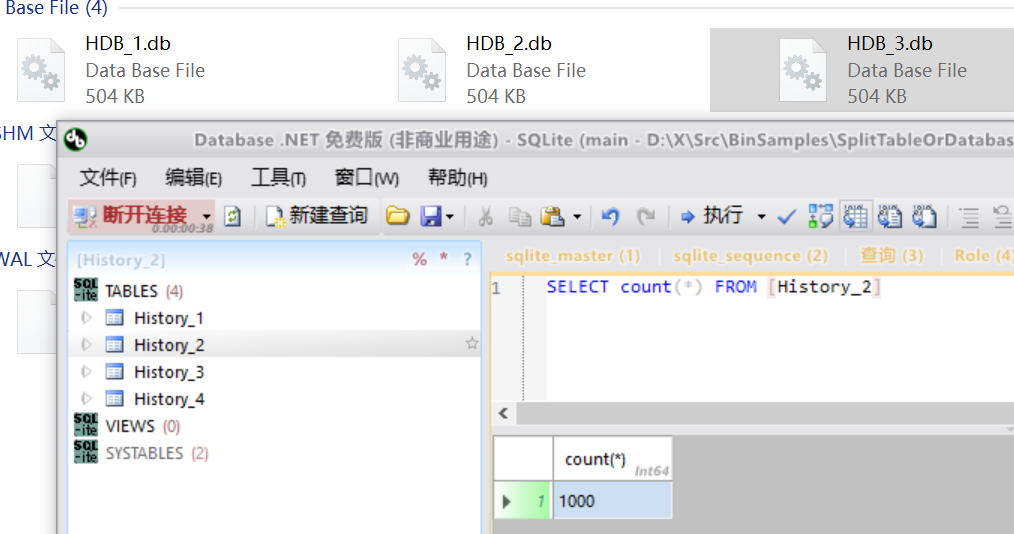
连接字符串指定的numberData目录下,生成了4个数据库,每个数据库生成了4张表,每张表内插入1000行数据。
指定不存在的数据库和数据表时,XCode的反向工程将会自动建表建库,这是它独有的功能。(因异步操作,密集建表建库时可能有一定几率失败,重试即可)
按时间序列分表分库
日志型的时间序列数据,特别适合分表分库存储,定型拆分模式是,每月一个库每天一张表。
static void TestByDate()
{
XTrace.WriteLine("按时间分表分库,每月一个库,每天一张表");
// 预先准备好各个库的连接字符串,动态增加,也可以在配置文件写好
var start = DateTime.Today;
for (var i = 0; i < 12; i++)
{
var dt = new DateTime(start.Year, i + 1, 1);
var connName = $"HDB_{dt:yyMM}";
DAL.AddConnStr(connName, $"data source=timeData\\{connName}.db", null, "sqlite");
}
// 每月一个库,每天一张表
start = new DateTime(start.Year, 1, 1);
for (var i = 0; i < 365; i++)
{
var dt = start.AddDays(i);
History.Meta.ConnName = $"HDB_{dt:yyMM}";
History.Meta.TableName = $"History_{dt:yyMMdd}";
// 插入一批数据
var list = new List<History>();
for (var n = 0; n < 1000; n++)
{
var entity = new History
{
Category = "交易",
Action = "转账",
CreateUserID = 1234,
CreateTime = DateTime.Now,
Remark = $"[{Rand.NextString(6)}]向[{Rand.NextString(6)}]转账[¥{Rand.Next(1_000_000) / 100d}]"
};
list.Add(entity);
}
// 批量插入。两种写法等价
//list.BatchInsert();
list.Insert(true);
}
}时间序列分表看起来比数字散列更简单一些,分表逻辑清晰明了。
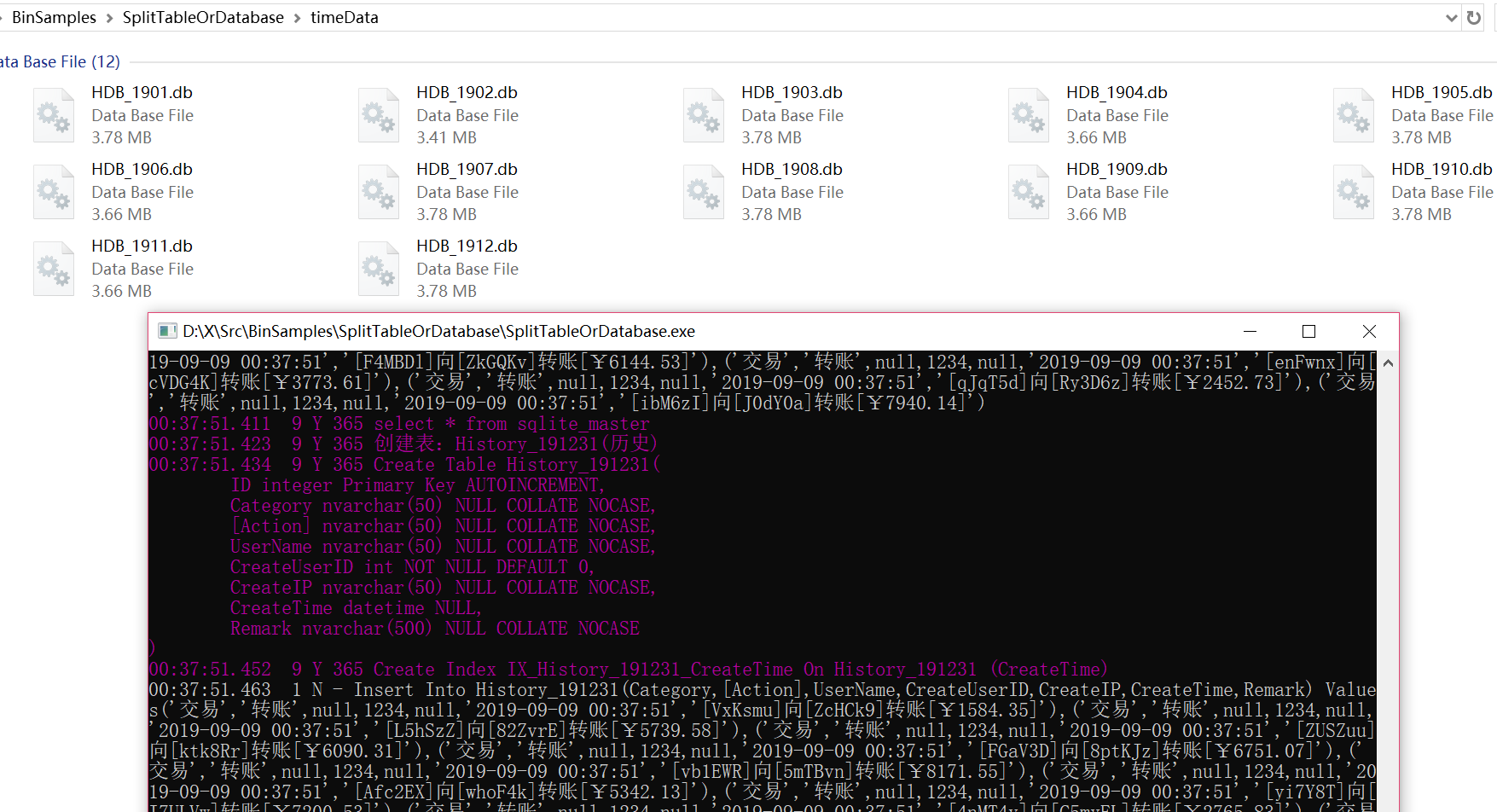
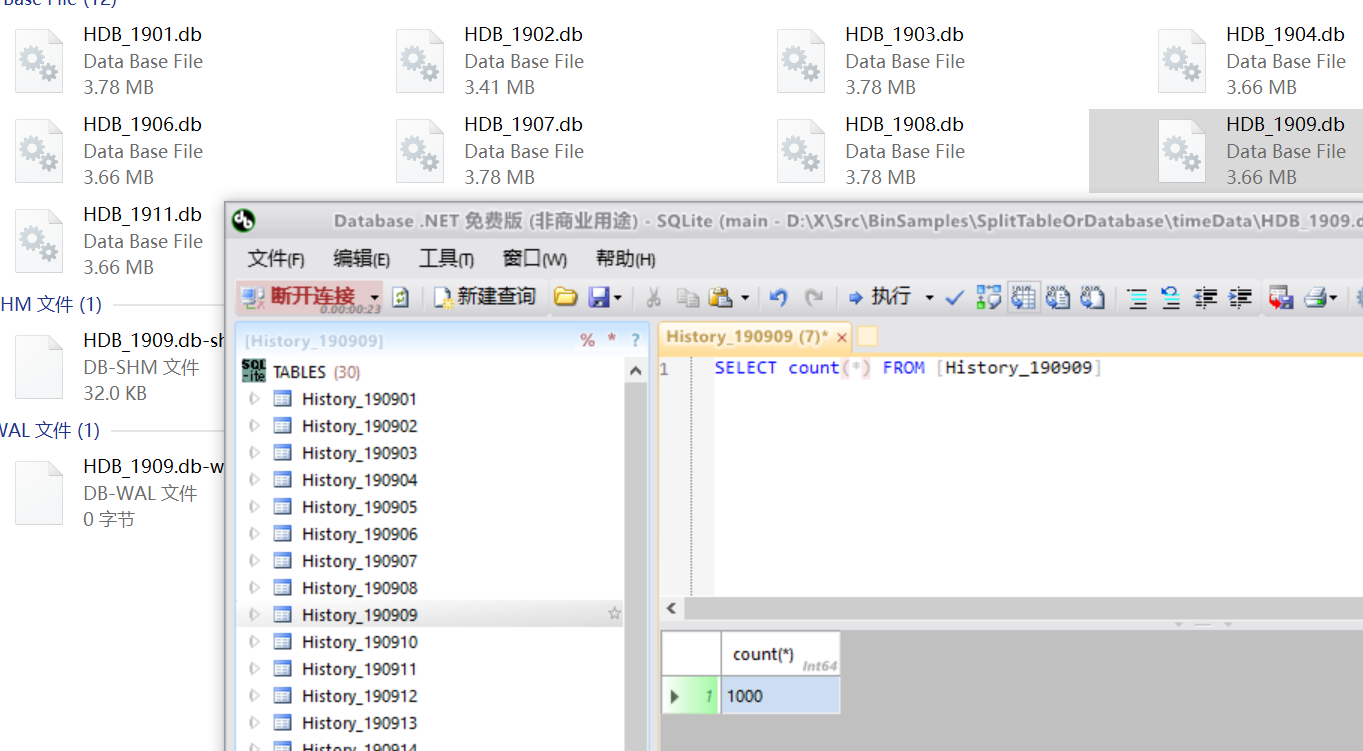
例程遍历了今年的365天,在连接字符串指定的timeData目录下,生成了12个月份数据库,然后每个库里面按月生成数据表,每张表插入1000行模拟数据。
综上,分表分库其实就是在操作数据库之前,预先设置好 Meta.ConnName/Meta.TableName,其它操作不变!
分表查询
说到分表,许多人第一反应就是,怎么做跨表查询?
不好意思,不支持!
只能在多张表上各自查询,如果系统设计不合理,甚至可能需要在所有表上进行查询。
不建议做视图union,那样会无穷无尽,业务逻辑还是放在代码中为好,数据库做好存储与基础计算。
分表查询的用法与分表添删改一样:
static void SearchByDate()
{
// 预先准备好各个库的连接字符串,动态增加,也可以在配置文件写好
var start = DateTime.Today;
for (var i = 0; i < 12; i++)
{
var dt = new DateTime(start.Year, i + 1, 1);
var connName = $"HDB_{dt:yyMM}";
DAL.AddConnStr(connName, $"data source=timeData\\{connName}.db", null, "sqlite");
}
// 随机日期。批量操作
start = new DateTime(start.Year, 1, 1);
{
var dt = start.AddDays(Rand.Next(0, 365));
XTrace.WriteLine("查询日期:{0}", dt);
History.Meta.ConnName = $"HDB_{dt:yyMM}";
History.Meta.TableName = $"History_{dt:yyMMdd}";
var list = History.FindAll();
XTrace.WriteLine("数据:{0}", list.Count);
}
// 随机日期。个例操作
start = new DateTime(start.Year, 1, 1);
{
var dt = start.AddDays(Rand.Next(0, 365));
XTrace.WriteLine("查询日期:{0}", dt);
var list = History.Meta.ProcessWithSplit(
$"HDB_{dt:yyMM}",
$"History_{dt:yyMMdd}",
() => History.FindAll());
XTrace.WriteLine("数据:{0}", list.Count);
}
}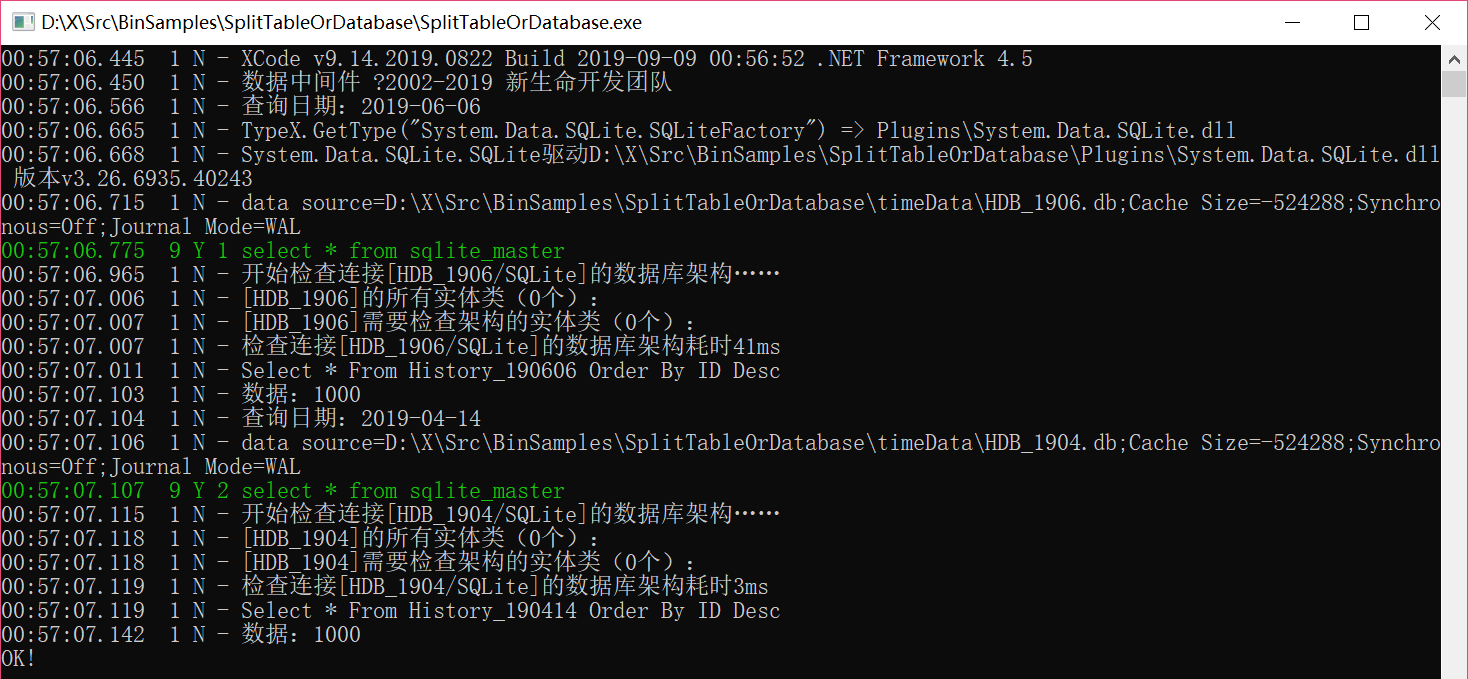
仍然是通过设置 Meta.ConnName/Meta.TableName 来实现分表分库。日志输出可以看到查找了哪个库哪张表。
这里多了一个 History.Meta.ProcessWithSplit ,其实是快捷方法,在回调内使用连接名和表名,退出后复原。
分表分库后,最容易犯下的错误,就是使用时忘了设置表名,在错误的表上查找数据,然后怎么也查不到……
分表策略
根据这些年的经验:
- Oracle适合单表1000万~1亿行数据,要做分区
- MySql适合单表1000万~5000万行数据,很少人用MySql分区
如果统一在应用层做拆分,数据库只负责存储,那么上面的方案适用于各种数据库。
同时,单表数据上限,就是大家常问的应该分为几张表?在系统生命周期内(一般1~2年),确保拆分后的每张表数据总量在1000万附近最佳。
根据《百亿级性能》,常见分表策略如下:
- 日志型时间序列表,如果每月数据不足1000万,则按月分表,否则按天分表。缺点是数据热点极为明显,适合热表、冷表、归档表的梯队架构,优点是批量写入和抽取性能显著;
- 状态表(订单、用户等),按Crc16哈希分表,以1000万为准,决定分表数量,向上取整为2的指数倍(为了好算)。数据冷热均匀,利于单行查询更新,缺点是不利于批量写入和抽取;
- 混合分表。订单表可以根据单号Crc16哈希分表,便于单行查找更新,作为宽表拥有各种明细字段,同时还可以基于订单时间建立一套时间序列表,作为冗余,只存储单号等必要字段。这样就解决了又要主键分表,又要按时间维度查询的问题。缺点就是订单数据需要写两份,当然,时间序列表只需要插入单号,其它更新操作不涉及。
至于是否需要分库,主要由存储空间以及性能要求决定。
分表与分区对比
还有一个很常见的问题,为什么使用分表而不是分区?
大型数据库Oracle、MSSQL、MySql都支持分区,前两者较多使用分区,MySql则较多分表。
分区和分表并没有本质的不同,两者都是为了把海量数据按照一定的策略拆分存储,以优化写入和查询。
- 分区除了能建立子索引外,还可以建立全局索引,而分表不能建立全局索引;
- 分区能跨区查询,但非常非常慢,一不小心就扫描所有分区;
- 分表架构,很容易做成分库,支持轻易扩展到多台服务器上去,分区只能要求数据库服务器更强更大;
- 分区主要由DBA操作,分表主要由程序员控制;
!!!某项目使用XCode分表功能,已经过生产环境三年半考验,日均新增4000万~5000万数据量,2亿多次添删改,总数据量数百亿。