NewLife.XCode是一个有10多年历史的开源数据中间件,支持nfx/netcore,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode。
整个系列教程会大量结合示例代码和运行日志来进行深入分析,蕴含多年开发经验于其中,代表作有百亿级大数据实时计算项目。
开源地址:https://github.com/NewLifeX/X (求star, 754+)
本文之前请先阅读
内置查询
扩展查询
前文《实体类详解》中有讲到扩展查询,XCode生成实体类代码时,在模型类有一个region叫“扩展查询”,一般是FindByAbc/FindAllByAbc的形式。
扩展查询以数据表索引为依据来生成:
- 唯一索引(含主键)生成FindByAbc方法(如FindByName),返回单个对象;
- 非唯一索引生成FindAllByAbc方法(如FindAllByClassID),返回对象列表(非null);

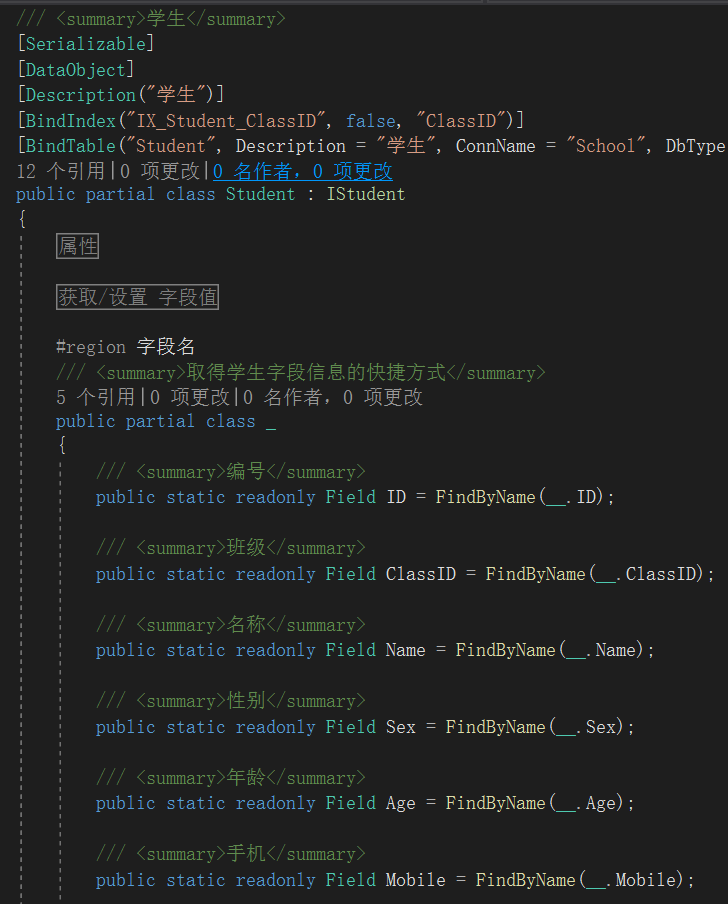
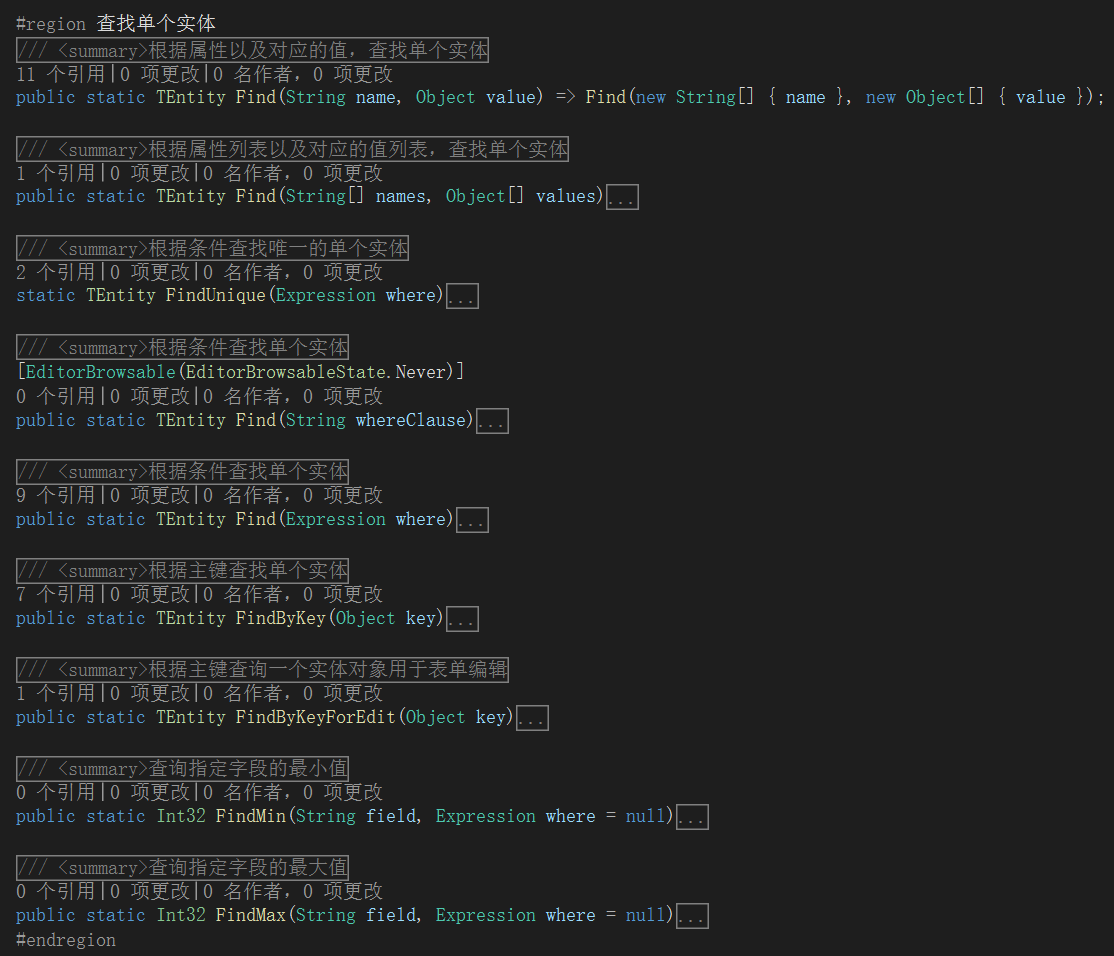
如上图,可知Entity实体基类内部,查询方法分为单对象查询的Find和对象列表的查询FindAll。
实际上,Find最终调用FindAll方法查一行。
Find/FindAll有多个重载,最主要的地方都是构造where查询条件。
下划线_是每个实体类都有的内嵌类,它包含了每一个字段的Field引用,借助运算符重载,可以很方便的构造查询条件,例如上面的_.Name == name最终会生成 where Name='Stone'
因为是内嵌类,在实体类内部使用的时候非常方便。但要是想要实体类外部使用,就麻烦很多了,需要带上实体类类名。
原则:XCode是充血模型,不管多么简单的查询,建议都封装Find/FindAll/Search等方法供外部使用。
高级表达式查询
仅靠一两个字段的简单查询,肯定无法满足各种业务要求,我们需要更强大的查询支持,特别是根据不同条件拼接不同语句。
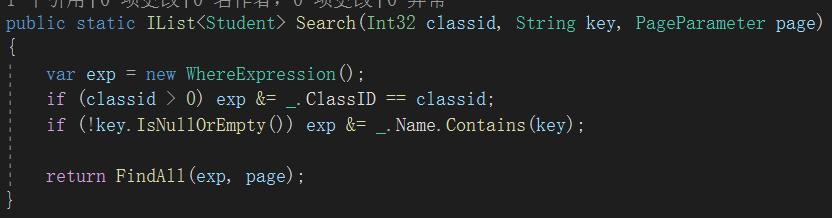
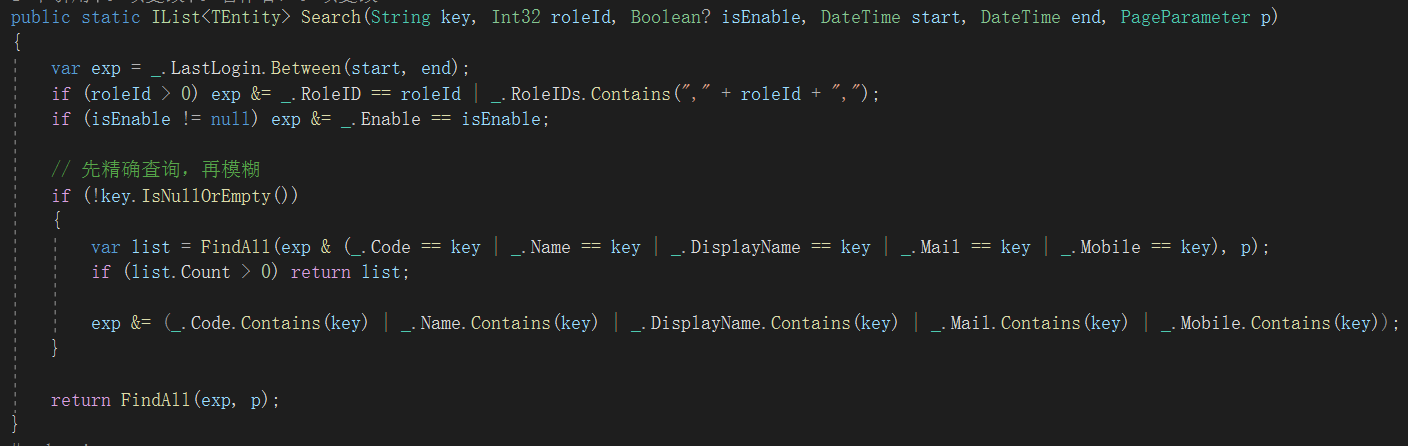
上面是两个非常典型的业务查询。
这里请出了条件表达式WhereExpression,实际上它只有两个功能,&表示And,|表示Or,根据表达式级别支持括号运算。
exp&=xxx 是最常用的写法,右边一般是各种Field表达式。
上面第一个例子,生成的查询语句可能是 select * from Student where classid=?classid and name like '%?key%'
为什么说“可能”?因为classid为0,或者key为空时,并不会参与拼接查询语句。
第二个例子稍微复杂一些,首先对key进行精确查询,找到了就返回,若是没找到,则开启模糊查询。
这里遇到了等于、包含、区间等判断操作,后面会详解所有支持的操作。
如非必要,建议保留select * 的查询方式,而不是指定列。
码农法则:数据库压力小于100qps时不要考虑指明select列来优化,大多数系统活不到需要优化的明天!
高级分页
两个例子都出现了一个PageParameter参数page,这是分页参数,包含分页查询以及排序所需要的数据。

- PageIndex和PageSize指定页序号和每页大小,这是内部建立分页查询的核心依据;
- Sort 指定排序字段,Desc 指定是否降序(默认升序);
- RetrieveTotalCount 指定是否获取总记录数,若为true,则在查询记录集之前,先查询满足条件的总行数TotalCount,用于分页PageCount。此时等于执行两次数据库查询;
- RetrieveState 指定是否获取统计 State,若为true,则在查询记录集之后,执行聚合查询,对数字型字段使用Sum聚合。此时最多可能执行3次数据库查询;
在执行FindAll查询时,若有传入 PageParameter 且 RetrieveTotalCount 为true,则先查询满足条件的记录数,大于0时才查某一页数据。
如果 Meta.Count 评估认为本表总行数超过100万,且FindAll查询没带有条件,则page.TotalCount直接取Meta.Count(少量偏差),以避免极大的FindCount耗时。
100万行以上数据表,如若不带条件或者条件没有命中索引,select count 将会极其的慢,在1000万以上甚至查不出来,这是XCode能对100亿表进行分页查询的关键所在。
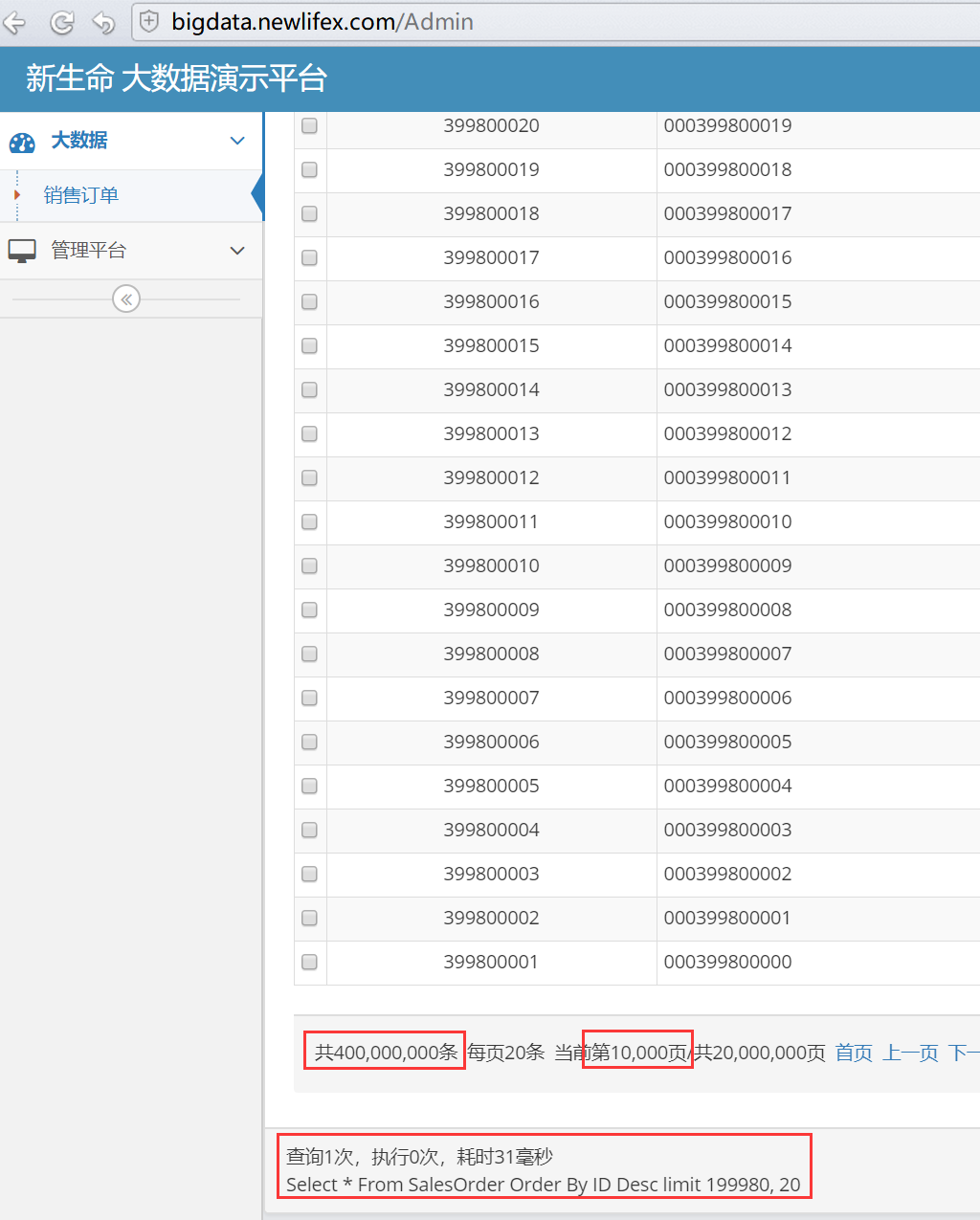
Meta.Count 的初始值来自于数据库元数据索引表,里面有该表主键的总行数,取得该值后如果小于100万再异步select count一次。
10多年前博客园ORM大战的时候,我们常说,等你支持千万级分页的时候再来比,就是钻了select count很慢的这个空子,很多人count出来总数再分页 ^_^
上图4亿数据,查询第10000页,在SQLite单表上,阿里云1C1G服务器。
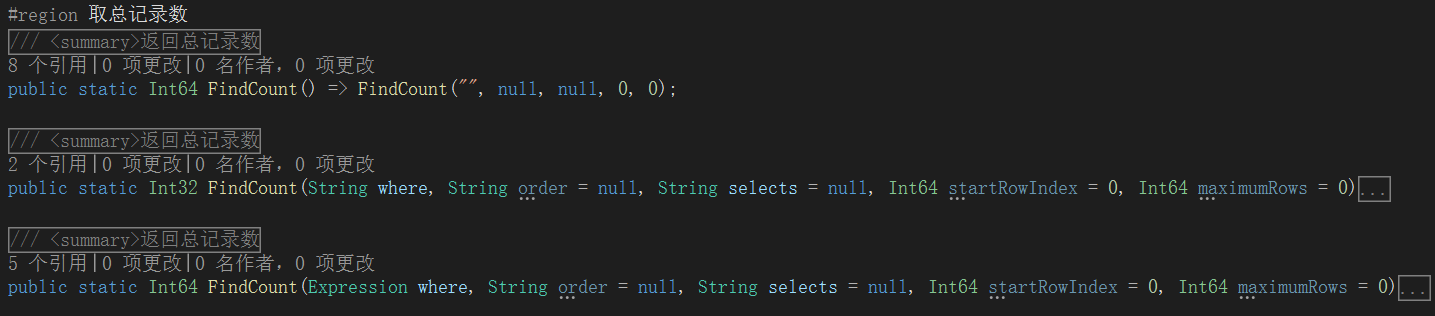
FindCount 分页
在早期版本,不支持RetrieveTotalCount ,只能通过 FindCount 取得满足该条件的总记录数,然后进行分页,至今仍然支持传统方法。
因此可以看到,FindAll 和 FindCount 都是成对出现,参数一摸一样。
并且 FindCount 方法也会带有分页参数,虽然用不到,但.NET2.0时代的 ObjectDataSource 要求两者的参数名称和顺序必须一致。
所有 FindCount 方法,将会得到 select count 查询语句,因此千万级大表需要慎用。
PageSplit 分页
内置支持的各种数据库,都有实现普通查询语句转为分页语句的 PageSplit(sql, start, maxNums) 方法。
MySql/SQLite/PostgreSQL 能够很好支持,只需要在 sql 后加上 limit start, maxNums 即可;
Oracle/SqlServer/Access/SqlCe 则要麻烦一次,其中SqlServer最复杂,不同版本的分页方法还不同,早期版本还要求有主键字段;
因此,sql 必须是简单的单表查询语句,PageSplit 才能把任意查询拆开并转换为分页查询。
大表分页优化
大表分页查询,开头会很快,越是往后越慢!
XCode采用倒置优化法,对于超过100万行(借助Meta.Count评估)的表,如果查询页超过中线,则从另一个方向查询,然后再把结果倒置回来。
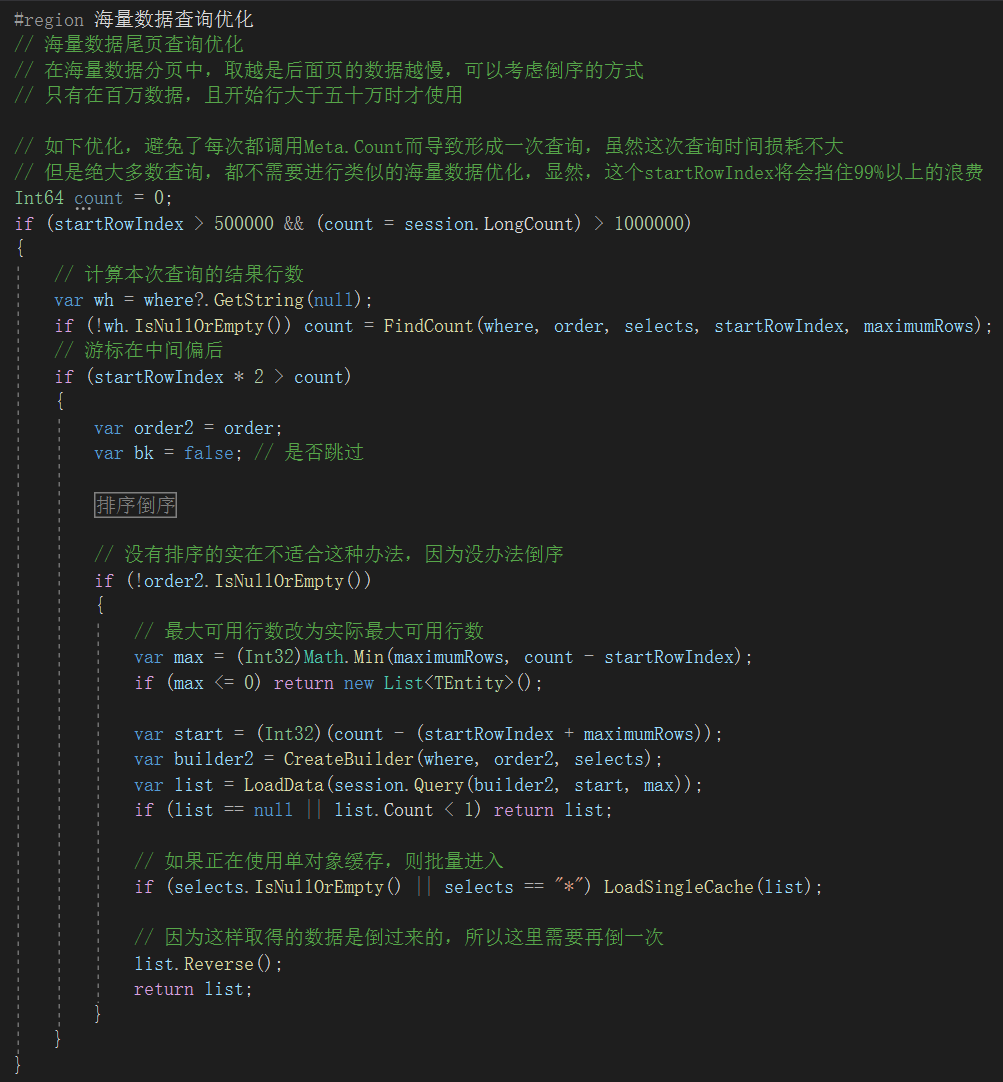
XCode要求数据查询必须考虑分页,没有分页的系统一般死在100万行以内。
Field扩展
内嵌类_引用的字段是Field,它继承自FieldItem。
Field/FieldItem全部功能:
- Equal 等于,操作符==
- NotEqual 不等于,操作符!=
- 大于操作符>,大于等于>=
- 小于操作符<,小于等于<=
- StartsWith 字符串开始,like '{0}%'。(支持索引)
- EndsWith 字符串结束,like '%{0}'
- Contains 字符串包含,like '%{0}%'
- In 集合包含,支持列表集合、字符串子查询和SelectBuilder子查询,集合只有一个元素时转为相等操作
- NotIn 集合不包含,支持列表集合、字符串子查询和SelectBuilder子查询,集合只有一个元素时转为不相等操作
- IsNull 是否空
- NotIsNull 不是空
- IsNullOrEmpty 字符串空或零长度
- NotIsNullOrEmpty 字符串非空非零长度
- IsTrue 是否True或者False/Null,参数决定两组之一
- IsFalse 是否False或者True/Null,参数决定两组之一
- Between 时间区间,大于等于开始,小于结束,如果开始结束都只有日期而没有时分秒,则结束加一天,如(2019-04-17, 2019-04-17)查 time>='2019-04-17' and time<2019-04-18'
排序字句/分组聚合
- Asc,升序
- Desc,降序。order by name desc
- GroupBy,分组。group by name
- As,聚合别名
- Count,计数
- Sum,求和
- Min,最小
- Max,最大
- Avg,平均
查询的本质
查询的本质是五参数版FindAll(where, order, selects, start, maxnums),其它查询方式都由它转化而来!
Entity实体基类封装了各种常用的查询方法:
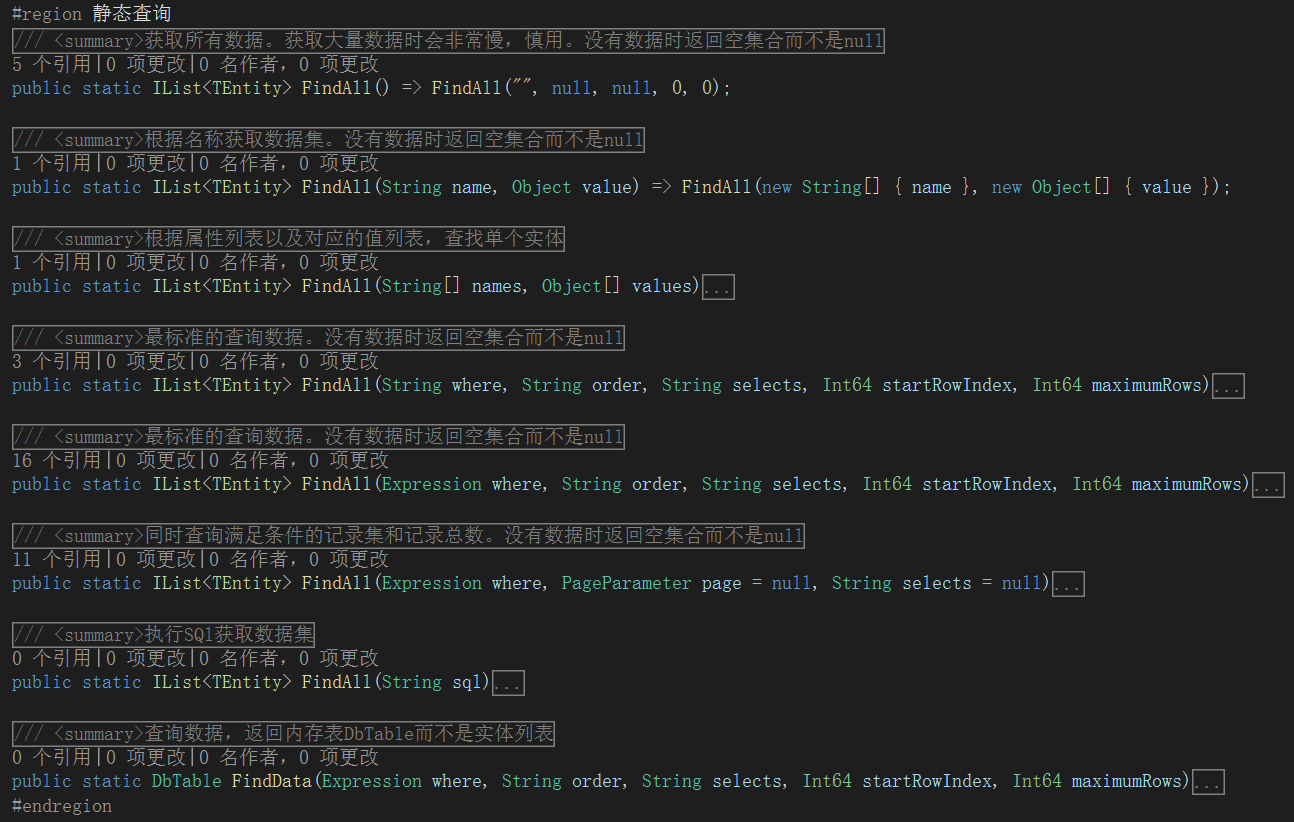
对于单表查询的XCode来说,五参数版FindAll很容易得到 select [selects] from [table] where [where] order by [order] limit [start], [maxnums] 语句,根据这个理念,FindAll可以支持任意复杂查询!
最终查询语句,由SelectBuilder类承载。
多表子查询
XCode不支持多表Join关联,这在前面《扩展属性》中提到过。
扩展属性固然可以解决关联多表字段的问题,并且借助缓存性能还不错,但是需要同时在两张表上设置条件的时候,就行不通了。
于是,需要用到高级查询,可以用子查询 来替代,正是前面说到的FieldItem.In扩展。
要查询名为“992班”的所有学生,一般这样写:
select * from student s inner join class c on s.classid=c.id where c.name='992班'XCode从2008年起,就放弃支持多表关联,自然也就不支持这样的写法。
在一般系统里面,班级表数据不多,可以借助实体缓存或者对象缓存:
// Class.FindByName 内部用缓存 var cls = Class.FindByName("992班"); var list = Student.FindAll(Student._.ClassID==cls.ID); // select * from student where classid=1234
但如果主表从表都是百万级大表,或者从表查询条件比较复杂,缓存就有点难以为继了。
于是有了子查询:
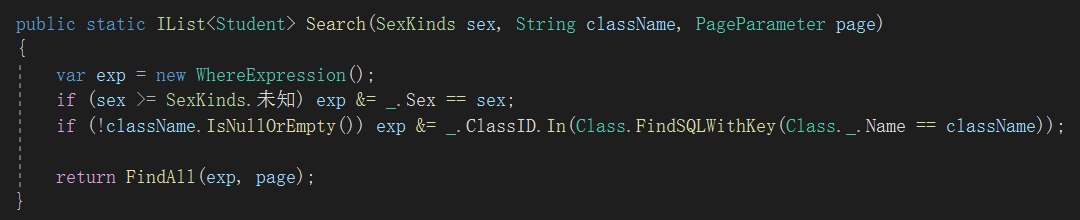
调用方法:
var list = Student.Search(SexKinds.女, "992班", p);得到结果:
select * from student where sex=2 and classid in(select id from class where name='992班')至此,绝大部分多表关联复杂查询语句,可以转化为子查询 !
跨库大表关联查询
实际项目开发中,还可能遇到更为复杂的场景。
场景:汽车表CarInfo有UserId字段,用户表User有DepartmentId字段,要求查询当前用户所在部门所有人的汽车信息,但是汽车表和用户表位于不同数据库(甚至可能异构MySql+Oracle)。
初级解法
var list = CarInfo.FindAll(_.UserId.In(User.FindSQLWithKey(User._.DepartmentId==.DepartmentId)));这是子查询写法,由于两个表在不同数据库,所以它无法正常工作。
高级解法
var users = User.FindAll(_.DepartmentId==.DepartmentId); // 先把本部门的人都查出来 var list = CarInfo.FindAll(_.UserId.In(users.Select(e=>e.Id))); // 再查汽车信息
这是跨库表的标准做法,如果用户表信息不到一万,第一行甚至可能在内存中就已经完成;
缺点也很明显,如果用户表过大(我们这里就过百万),本部门的人员就可能有数千,二次查询时In会直接失败(一般不支持超过1000项)
神级解法
(针对亿级数据表CarInfo关联百万级基础表User)
// CarInfo ( * + UserId + DeparmentId) // 业务层只需要给UserId赋值,在CarInfo添加或更新时执行Valid,自动补上DeparmentId,等于不改变原有逻辑 // 当然,如果业务层方便直接给DeparmentId赋值,那是再好不过了,双保险吧 public override void Valid(Boolean isNew) { // 如果业务层没有给DeparmentId赋值,这里补上 if (UserId > 0 && !Dirty[__.DeparmentId]) { var user = User.FindById(UserId); // User.FindById 走对象缓存 if (user != null) DeparmentId = user.DeparmentId; } } // 最终直接查询 var list = CarInfo.FindAll(_.DeparmentId == .DeparmentId);
该方法通用性强,实力强大,但也不推荐随意使用,毕竟工作量增加了很多很多。
解法的选择,取决于数据量,在数据量固定的情况下,选择简单的解法更好。
如果对你有帮助,给个赞呗!


分组与统计请阅读